u=(u1,…,un), kde ui:A→R je užitková funkce i-tého hráče
Definition: Strategies
čistá (pure) strategie si hráče i je akce z Ai
profil čistých strategií je n-tice čistých strategií (akcí) – za každého z n hráčů je tam jedna
smíšená (mixed) strategie si hráče i je pravděpodobnostní distribuce přes Ai
tedy si(ai)∈[0,1] a ∑ai∈Aisi(ai)=1
profil smíšených strategií je n-tice smíšených strategií
každá čistá strategie je smíšená
Definition: Expected payoff
ve hře G=(P,A,u) je expected payoff (střední hodnota výplatní funkce) pro hráče i z profilu smíšených strategií s určena vzorcem ui(s)=a∈A∑ui(a)⋅P(a)j=1∏nsj(aj)
platí linearita střední hodnoty výplatní funkce ui(s)=ai∈Ai∑si(ai)⋅ui(ai;s−i)
Example: Five basic games
vězňovo dilema
matching pennies
battle of sexes
game of chicken
bitva o duši Gothamu
Nash equilibrium
Definition: Best response
best response i-tého hráče na strategický profil s−i je smíšená strategie si∗ taková, že ∀si′∈Si:ui(si∗;s−i)≥ui(si′;s−i)
kdyby hráč i znal strategie ostatních, zvolil by si strategii si∗, protože maximalizuje jeho očekávanou výplatu, pokud ostatní hrají s−i
Definition: Nash equilibrium
mějme hru G=(P,A,u) v normální tvaru s n hráči
pak Nashovo ekvilibrium (NE) ve hře G je strategický profil (s1,…,sn) takový, že si je best response hráče i na s−i pro každé i∈P
tedy žádný hráč by neměnil svou strategii, kdyby znal strategie ostatních
Theorem: Nash’s Theorem
Nashova věta: každá hra v normálním tvaru má Nashovo ekvilibrium
pomocné definice a tvrzení
X⊆Rd je kompaktní, pokud je uzavřená a omezená
Y⊆Rd je konvexní, pokud (∀x,y∈Y)(∀α∈[0,1]):αx+(1−α)y∈Y
pro n afinně nezávislých bodů x1,…,xn∈Rd definujeme (n−1)-simplex Δn na x1,…,xn jako množinu konvexních kombinací bodů x1,…,xn
každý simplex je kompaktní konvexní množina v Rd
lemma: pokud K1,…,Kn jsou kompaktní množiny a ∀i:Ki⊆Rdi, pak K1×⋯×Kn je kompaktní množina v Rd1+⋯+dn
Brouwerova věta o pevném bodu: pokud K⊆Rd je neprázdná kompaktní konvexní množina a f:K→K je spojité zobrazení, pak existuje pevný bod x0∈K pro f, tedy f(x0)=x0
důkaz Nashovy věty
nechť K=S1×⋯×Sn je množina všech smíšených strategií
Si … množina smíšených strategií hráče i
každá množina Si je simplex, takže je kompaktní a konvexní
proto i K je kompaktní
pro libovolné s,s′∈K a α∈[0,1] je αs+(1−α)s′ také smíšený strategický profil v K, tedy K je konvexní
pro hráče i∈S a akci ai∈A definujeme zobrazení φi,ai:K→R tak, že φi,ai(s)=max{0,ui(ai;s−i)−ui(s)}
tato funkce vyjadřuje, o kolik by si hráč polepšil, kdyby místo si hrál akci ai (pokud by si nepolepšil, je nulová)
z definice ui je toto zobrazení spojité
pro s∈K definujeme nový „vylepšený“ strategický profil s′∈K tak, že přidáme pravděpodobnost akcím, které jsou lepšími odpověďmi na s−i
pokud je s∈K Nashovo ekvilibrium, pak všechny φ jsou nulové a f(s)=s, tedy s je pevný bod funkce f
pokud je s∈K pevným bodem funkce f…
zvolíme libovolného hráče i∈P
v supportu si existuje akce ai′∈Ai taková, že ui(ai′;s−i)≤ui(s)
jinak by platilo ui(s)<∑aisi(ai)ui(ai;s−i), což je spor s linearitou střední hodnoty výplatní funkce
support si … akce ∈Ai, které si nemapuje na nulu
pro tuto akci ai′ nutně platí φi,ai′=0 (díky té nerovnosti)
tak získáme si′(ai′)=1+∑bi∈Aiφi,bi(s)si(ai′)
s je pevný bod, proto si′(ai′)=si(ai′), tedy ve jmenovateli musí být jednička a suma bude nulová
proto ui(s)≥ui(bi;s−i) pro každé bi∈Ai
z toho vyplývá, že pro libovolnou smíšenou strategii si′′∈Si platí ui(si′′;s−i)=bi∈Ai∑si′′(bi)ui(bi;s−i)≤bi∈Ai∑si′′(bi)ui(s)=ui(s)
levá rovnost z linearity, nerovnost z nerovnosti výše, pravá rovnost z jednotkového součtu pravděpodobností
tedy si je best response hráče i na s−i a s je smíšené Nashovo ekvilibrium hry G
Definition: Pareto optimality
strategický profil s v G Pareto dominuje s′, píšeme s′≺s, pokud…
∀i∈P:ui(s)≥ui(s′)
∃j∈P:uj(s)>uj(s′)
≺ je částečná uspořádání množiny S všech strategických profilů hry G
za nejlepší výsledky G se považují maxima S podle ≺
strategický profil s∈S je Pareto optimální, pokud neexistuje jiný profil, který ho dominuje
ve hrách nulového součtu jsou všechny strategické profily Pareto optimální
ne všechna Nashova ekvilibria jsou Pareto optimální (viz vězňovo dilema)
Zero-sum games
Definition: Zero-sum game and its representation
G=(P,A=A1×A2,u)
∀a∈A:u1(a)+u2(a)=0
pokud ∣A1∣=m a ∣A2∣=n, pak můžeme G reprezentovat pomocí výplatní matice M∈Rm×n, kde Mij=u1(i,j)=−u2(i,j)
pro strategický profil (s1,s2) uvažujeme vektory smíšených strategií x,y takové, že xi=s1(i) a podobně yi=s2(j)
pak platí u1(s)=xTMy=−u2(s)
Definition: Worst-case optimal strategies
best response druhého hráče je vektor y∈S2, který minimalizuje xTMy
best response prvního hráče je vektor x∈S1, který maximalizuje xTMy
β(x)=miny∈S2xTMy je nejlepší očekávaný payoff druhého hráče proti x
α(y)=maxx∈S1xTMy je nejlepší očekávaný payoff prvního hráče proti y
strategický profil (x,y) je NE, právě když β(x)=xTMy=α(y)
pokud první hráč předpokládá, že druhý hráč vždy zvolí best response na každou jeho strategii, a snaží se maximalizovat payoff za tohoto předpokladu, zvolí strategii x∈S1
pro tuto „worst-case optimal strategy“ platí β(x)=maxx∈S1β(x)
podobně worst-case optimal strategy je taková strategie y∈S2, že α(y)=miny∈S2α(y)
Theorem: Worst-case optimal strategies and NE
lemma
(∀x∈S1)(∀y∈S2):β(x)≤xTMy≤α(y)
pokud je strategický profil (x∗,y∗) Nashovým ekvilibriem, pak jsou obě strategie worst-case optimální
libovolné strategie x∗∈S1 a y∗∈S2 splňující β(x∗)=α(y∗) tvoří Nashovo ekvilibrium (x∗,y∗)
důkaz
přímo z definice β,α (jedno definujeme jako minimum, druhé jako maximum)
z (1) vyplývá ∀x∈S1:β(x)≤α(y∗)
(x∗,y∗) je NE, proto β(x∗)=α(y∗)
tedy ∀x∈S1:β(x)≤β(x∗)
proto x∗ je worst-case optimální pro prvního hráče, podobně y∗ pro druhého hráče
pokud β(x∗)=α(y∗), pak (1) implikuje β(x∗)=(x∗)TMy∗=α(y∗)
Theorem: The Duality Theorem
lineární program P lze vyjádřit v kanonickém tvaru jako maximalizaci cTx při omezujících podmínkách Ax≤b a x≥0
k primárnímu programu P najdeme duální program D, kde minimalizujeme bTy při omezujících podmínkách ATy≥c a y≥0
věta
pokud oba lineární programy P,D mají přípustná řešení, pak mají oba optimální řešení
navíc, pokud x∗ a y∗ jsou optimální řešení pro P a D po řadě, pak cTx∗=bTy∗, to znamená maximum P se rovná minimu D
Theorem: The Minimax Theorem
věta
pro každou hru s nulovým součtem platí, že worst-case optimální strategie pro oba hráče existují a mohou být efektivně spočteny
existuje číslo v takové, že pro libovolné worst-case optimální strategie x∗,y∗ je strategický profil (x∗,y∗) Nashovým ekvilibriem a β(x∗)=(x∗)TMy∗=α(y∗)=v
důkaz
pro pevné x∈S1 určíme best response druhého hráče
použijeme lineární program P s proměnnými y1,…,yn
minimalizuj xTMy za podmínek ∑yj=1 a y≥0
jeho duál je D s proměnnou x0
maximalizuj x0 za podmínky 1x0≤MTx
podle věty o dualitě mají oba programy stejné optimum β(x)
z x uděláme vektor proměnných x1,…,xm
tak získáme lineární program D′ s proměnnými x0,x1,…,xm
maximalizuj x0 za podmínek:
1x0−MTx≤0
∑i=1mxi=1
x≥0
optimum x∗ programu D′ je worst-case optimální strategie pro prvního hráče
podobně lze nalézt worst-case optimální strategii pro druhého hráče
minimalizuj y0 za podmínek:
1y0−My≥0
∑j=1nyj=1
y≥0
nyní zbývá ukázat, že (x∗,y∗) je NE a β(x∗)=(x∗)TMy∗=α(y∗)=v
z věty o dualitě vidíme, že P′ a D′ mají stejné optimum β(x∗)=x0∗=y0∗=α(y∗), což je požadované v
z části (3) lemmatu o worst-case optimálních strategiích vyplývá, že jsme našli NE a také rovnost β(x∗)=(x∗)TMy∗=α(y∗)
Bimatrix games
Definition: Bimatrix game, nondegenerate bimatrix game
maticová hra (bimatrix game) je hra dvou hráčů v normálním tvaru
G=({1,2},A=A1×A2,u)
∣A1∣=m, ∣A2∣=n
výplatní funkce u1,u2 reprezentujeme maticemi M,N∈Rm×n
Mij=u1(i,j)
Nij=u2(i,j)
tedy akce prvního hráče odpovídají řádkům, akce druhého sloupcům
uvažujeme-li vektory smíšených strategií x,y, pak platí u1(s)=xTMy a u2(s)=xTNy
maticová hra je nedegenerovaná, pokud ke každé smíšené strategii se supportem velikosti k existuje nejvýše k čistých best responses
Theorem: Best response condition
definice: support (nosič) smíšené strategie si je množina {ai∈Ai:si(ai)>0}
pozorování (best response condition): ve hře G=(P,A,u) pro každého hráče platí, že smíšená strategie si je best response na s−i, právě když všechny čisté strategie v supportu si jsou best responses na s−i
důkaz ⟸
nechť každé ai∈Supp(si) splňuje ui(ai;s−i)≥ui(si′;s−i) pro každé si′∈Si
pak pro každé si′∈Si z linearity ui vyplývá ui(s)=ai∈Supp(si)∑si(ai)ui(ai;s−i)≥ai∈Supp(si)∑si(ai)ui(si′;s−i)=ui(si′;s−i)
důkaz ⟹ (sporem)
nechť si je best response hráče i na s−i
předpokládejme, že existuje ai∈Supp(si), co není best response
pak existuje si′∈Si, kde ui(ai;s−i)<ui(si′;s−i)
jelikož si je best response na s−i, nutně si(ai)<1
z linearity ui najdeme a^i∈Supp(si), kde ui(a^i;s−i)>ui(ai;s−i)
definujeme novou smíšenou strategii si∗
si∗(ai)=0
si∗(a^i)=si(a^i)+si(ai)
jinak si∗(ai)=si(ai)
z linearity ui dostaneme ui(si∗;s−i)=ai∈Ai∑si∗(ai)ui(ai;s−i)>ai∈Ai∑si(ai)ui(ai;s−i)=ui(s)
což je spor
Algorithm: Support enumeration
best response condition (BRC) v maticových hrách
u1(s)=xTMy,u2(s)=xTNy
podle BRC je x best response na y, právě když ∀i∈A1:xi>0⟹Mi,∗y=max{Mk,∗y∣k∈A1}
pro každý support platí, že jeho čistá strategie je maximální z čistých strategií
podobně y je best response na x, právě když ∀j∈A2:yj>0⟹Nj,∗Tx=max{Nk,∗Tx:k∈A2}
hledáme NE v nedegenerované maticové hře G
nechť I⊆A1 a J⊆A2 jsou supporty v G
sestavíme soustavu rovnic o ∣I∣+∣J∣+2 neznámých
∑i∈Ixi=1
∑j∈Jyj=1
∀j:Nj,∗Tx=v
∀i:Mi,∗y=u
u,v budou nabývat hodnot maxim plynoucích z BRC (viz výše)
také požadujeme nezápornost proměnných
pořád je ale nezbytné získat I,J, to za nás provede algoritmus
u nedegenerovaných her vyplývá přímo z BRC, že supporty strategií v Nashově ekvilibriu budou mít stejnou velikost
tedy můžeme projít všechny možné supporty I,J velikosti k∈{1,…,min{m,n}} a pro každou dvojici řešíme soustavu rovnic (pokud najdeme nezáporné řešení, máme NE)
algoritmus běží přibližně v čase 4n pro m=n
m=∣A1∣,n=∣A2∣
Definition: Best response polyhedra, best response polytope
mějme strategický profil s se smíšenými strategiemi x,y
polyedr nejlepších odpovědí
pro prvního hráče: P={(x,v)∈Rm×R:x≥0∧1Tx=1∧NTx≤1v}
pro druhého hráče: Q={(y,u)∈Rn×R:y≥0∧1Ty=1∧My≤1u}
poslední nerovnice My≤1u říká, že střední hodnota výplatní funkce u1(s) je nejvýše u, jelikož u1(s)=xTMy≤xT1u=u∑xi=u (podobné je to s nerovnicí NTx≤1v)
definujeme labels
bod (x,v)∈P má label i∈A1∪A2, pokud buď i∈A1∧xi=0, nebo i∈A2∧Ni,∗Tx=v (tedy pokud i∈A1 není v supportu nebo pokud i∈A2 je best response na x)
podobně (opačně) pro (y,u)∈Q
každý bod může mít více labels
(normalizovaný) polytop nejlepších odpovědí
předpokládám, že M,NT jsou nezáporné a nemají nulový sloupec (jednoduše přičteme velkou konstantu k výplatám)
každou nerovnost Ni,∗Tx≤v vydělíme v
xi/v bude naše nová proměnná
podobně pro Q
tak normalizujeme výplaty na jedničku a získáme (normalizované) polytopy nejlepších odpovědí
pro prvního hráče: P={x∈Rm:x≥0∧NTx≤1}
pro druhého hráče: Q={y∈Rn:y≥0∧My≤1}
nerovnosti mají stejné významy (co se týče supportu / best response)
z předpokladu na M,N jsou polyedry P,Q omezené (jsou to polytopy) a mají dimenze m a n
nevýhoda: složky x a y se nesečtou na jedničku, takže je musíme přeškálovat
polytop P odpovídá P∖{0} podle projektivní transformace (x,v)↦x/v (podobně Q odpovídá P∖{0})
projektivní transformace zachovává incidence, tedy labels zůstávají stejné
Theorem: NE and Best response polyhedra/polytope
tvrzení: strategický profil s je NE, právě když je pár ((x,v),(y,u))∈P×Q kompletně označen, tedy každý label i∈A1∪A2 se objevuje jako label (x,v) nebo (y,u)
důkaz
podle best response condition je si best response na s−i, právě když všechny čisté strategie supportu si jsou best responses na s−i
pokud chybí label i, znamená to, že i je v supportu, ale čistá strategie i není best response
pokud má dvojice bodů dohromady všechny labely, pak s1 a s2 jsou navzájem best responses, jelikož každá čistá strategie je buď best response, nebo není v supportu
pak je s Nashovo ekvilibrium
důsledek pro polytop
strategický profil s je NE, právě když je bod (x/u2(s),y/u1(s))∈P×Q∖{(0,0)} kompletně označen
Algorithm: Vertex enumeration
z nedegenerovanosti G víme, že každý bod P má nejvýše m labels, podobně každý bod Q má nejvýše n labels (pro k prvků supportu je nejvýše k best responses)
labely odpovídají stěnám polytopu, proto pouze vrcholy můžou mít přesně m a n labels (je to prostý polytop, žádné body nemají víc než m, respektive n vrcholů)
algoritmus
vstup: nedegenerovaná maticová hra G
výstup: všechna Nashova ekvilibria hry G
pro každou dvojici vrcholů (x,y) z (P∖{0})×(Q∖{0})
pokud je (x,y) kompletně označen, vrať (x/(1Tx),y/(1Ty)) jako Nashovo ekvilibrium
všechny vrcholy prostého polytopu v Rd s v vrcholy a N popisujícími nerovnostmi mohou být nalezeny v čase O(dNv)
ale pokud m=n, polytopy nejlepších odpovědí mohou mít cn vrcholů pro nějakou konstantu c∈(1,2.9)
hledání zrychlíme tak, že budeme sledoval labels (viz Lemke–Howson)
Algorithm: Lemke–Howson algorithm
P je prostý polytop dimenze m, každému jeho vrcholu přiléhá m hran a m stěn
každý vrchol polytopu P má m labels a každá hrana má m−1 labels
když „upustíme“ label ℓ∈A1∪A2 z vrcholu x polytopu P, znamená to, že se přesouváme po hraně P, která je incidentní s vrcholem x a má stejné labely jako x kromě ℓ
druhý konec hrany má stejné labels jako x, akorát místo ℓ má jiný label, který „sebereme“
podobně definujeme upouštění a sbírání labels v Q
algoritmus
začínáme v (0,0) a střídavě prochází po hranách v P a Q
v prvním kroku vybereme (náhodný) label k∈A1∪A2 a upustíme ho
pak sebereme nový label ℓ
ten má duplikát ve druhém polytopu
v dalším kroku tento duplikát upustíme a sebereme nový label ℓ′
takhle iterujeme pořád dál, zastavíme se v momentě, kdy ℓ′=k
duplikát buď odpovídá nové best response, která má kladnou pravděpodobnost, nebo čisté strategii, jejíž pravděpodobnost jsme vynulovali a přesouváme se směrem od její best response stěny
algoritmus vrací jedno Nashovo ekvilibrium v G, funguje pro nedegenerované maticové hry
správnost
věta: algoritmus zastaví po konečném počtu kroků a vrátí vektory smíšených strategií NE
nechť k je label vybraný v prvním kroku
sestavíme konfigurační graf G, kde jsou vrcholy tvořeny páry (x,y) vrcholů z P×Q, které jsou k-téměř kompletně označené (každý label z A1∪A2∖{k} je labelem x nebo y)
mezi vrcholy v G vede hrana, právě když se mezi dvojicí párů dá projít v jednom kroku algoritmu (jeden vrchol dvojice se nemění, druhý vrchol změníme průchodem po hraně polytopu)
G je zjevně konečný
G má vrcholy stupně 1 nebo 2 (tedy je to disjunktní sjednocení cest a cyklů)
pokud má (x,y) všechny labels z A1∪A2, pak je připojen k právě jednomu vrcholu, jelikož právě jeden z vrcholů x,y má k a můžeme ho upustit jenom z tohoto vrcholu
jinak x,y sdílejí jeden label a (x,y) je incidentní se dvěma hranami, jelikož duplikát můžeme upustit z vrcholu x nebo z vrcholu y
Lemke–Howson začíná v listu (0,0), prochází po cestě a do žádného vrcholu se nevrací, skončí na konci cesty v listu (x∗,y∗)
poznámka: v G jsou všechna Nashova ekvilibria, z každého z nich můžeme odebrat k, takže jsou vždy na konci cest
součet vrcholů stupně 1 musí být sudý, jeden z nich je (0,0), ostatní jsou NE, z čehož vyplývá, že v nedegerované maticové hře je lichý počet NE
Lemke–Howson vždy najde jedno NE
degenerované hry můžou mít nekonečně mnoho NE
algoritmus lze implementovat pomocí komplementárního pivotování
může běžet exponenciálně dlouho (O(2n) kroků pro n=m)
v praxi je dostatečně rychlý (polynomiální čas na uniformně náhodných hrách)
Theorem: Computational complexity of NASH
NASH = problém nalezení NE v maticových hrách
NASH není NP-úplný, protože víme, že NE vždycky existuje
třída FNP
vstupem FNP problému je instance problému z NP, algoritmus nám vrátí řešení, pokud existuje, jinak vrátí „ne“
NASH patří do FNP, protože ověření NE lze provést pomocí best response condition
ale NASH pravděpodobně není FNP-úplný, protože kdyby byl, NP = coNP
strukturu NASH lze zachytit jako hledání konce cesty v grafu stupně nejvýše 2 (viz důkaz korektnosti Lemke–Howsonova algoritmu)
problém END-OF-THE-LINE = pro orientovaný graf G, kde má každý vrchol nejvýše jednoho předchůdce a jednoho následníka, a zadaný vrchol s bez předchůdce najdi vrchol t=s bez předchůdce nebo následníka
G je specifikován tak, že funkce f(v), co běží v polynomiálním čase, vrací předchůdce a následníka v, pokud existují
tedy G může být exponenciálně velký vůči velikosti vstupu
PPAD je složitostní třída, kam spadají problémy, které lze v polynomiálním čase převést na END-OF-THE-LINE
NASH je PPAD-úplný (dokázáno v roce 2009)
pravděpodobně neexistuje polynomiální algoritmus pro NASH
hledání aproximace NE ve hrách s aspoň třemi hráči náleží PPAD, ale ten problém se zdá ostře těžší než PPAD
když upravíme NASH tak, aby jeho existence nebyla zaručena, výsledný problém se často stane NP-úplný
Example: Problems from PPAD
end-of-the-line
NASH (bimatrix, non-degenerate)
Sperner's lemma
ham sandwich theorem
Borsuk–Ulam theorem
Other notions of equilibria
Definition: ε-Nash equilibrium
pro ϵ>0 je strategický profil s ve hře G=(P,A,u)ε-Nashovým ekvilibriem, pokud pro každého hráče i∈P a každou si′∈Si platí ui(si;s−i)≥ui(si′;s−i)−ε
tedy žádná jiná strategie hráči nezlepší payoff o více než ε
pro ε=0 bychom získali klasické NE
výhody
jednoduchá definice
ε-NE vždycky existuje podle Nashovy věty (každé NE je ε-NE)
pokud použijeme ε jako „přesnost počítače“, nemusíme počítat s iracionálními čísly
FPTAS ani nemůže existovat, pokud neplatí, že PPAD⊆FP
ale máme kvazi-polynomiální algoritmus
věta: nechť G je hra dvou hráčů v normálním tvaru, každý z hráčů má m akcí takových, že výplatní matice obsahují hodnoty v intervalu [0,1], pak pro každé ε>0 existuje algoritmus, který spočítá ε-NE hry G v čase mO(logm/ε2)
Definition: Correlated equilibrium (CE)
ve hře G=(P,A,u) nechť p je pravděpodobnostní distribuce na A
tedy p(a)≥0 pro každé a∈A a ∑p(a)=1
distribuce p je korelované ekvilibrium (CE) v G, pokud (∀i∈P)(∀ai,ai′∈Ai):a−i∈A−i∑ui(ai;a−i)p(ai;a−i)≥a−i∈A−i∑ui(ai′;a−i)p(ai;a−i)
možný pohled
jako by důvěryhodná třetí strana samplovala a∈A podle známého rozdělení p a soukromě by doporučila každému hráči i strategii ai
každý hráč se doporučením může, ale nemusí řídit
p je CE, pokud každý hráč maximalizuje střední hodnotu užitku tak, že se řídí doporučením
Theorem: Properties of correlated equilibria
každé NE je CE, takže CE vždy existuje
každé NE s je CE s distribucí p=∏i=1nsi, takže CE může dávat lepší payoffs než NE
CE lze spočítat v polynomiálním čase pomocí lineárního programování, jako proměnné použijeme (p(a))a∈A
Regret minimization
Definition: Regret minimization model
máme agenta A v nepřátelském prostředí
agent A má N dostupných akcí z množiny X={1,…,N}
v každém kroku t=1,…,T
agent A zvolí pravděpodobnostní rozdělení pt=(p1t,…,pNt) nad X
pit … pravděpodobnost, že A zvolí i v kroku t
pak nepřítel zvolí ztrátový vektor ℓt=(ℓ1t,…,ℓnt)
ℓit∈[−1,1] … ztráta (loss) akce i v kroku t
agent A pak prodělá ztrátu ℓAt=∑i=1Npitℓit
to je střední hodnota ztráty agenta A v kroku t
kumulativní ztráta akce i po T krocích … LiT=∑t=1Tℓit
kumulativní ztráta agenta A … LAT=∑t=1TℓAt
pro zjednodušení budeme často uvažovat pouze ztrátové vektory ∈{0,1}N, ale vše lze zobecnit
Definition: External regret
uvažujme třídu agentů AX={Ai:i∈X}
Ai … agent, který vždy zvolí akci i
external regret agenta A … RAT=LAT−min{LBT∣B∈AX}
tedy RAT=LAT−min{LiT∣i∈X}
Theorem: External regret as a suitable metric
mohlo by se zdát, že AX obsahuje příliš jednoduché agenty, ale lze ukázat, že velké comparison classes vedou k velkému regretu
uvažujme Aall třídu agentů, kteří v každém kroku zvolí náhodou akci z X (přiřadí jí pravděpodobnost 1)
pozorování: pro libovolného agenta A a každé T∈N existují posloupnost T ztrátových vektorů a agent B∈Aall takoví, že LAT−LBT≥T(1−1/N)
horší už to pomalu ani být nemůže
důkaz
pro každé t ať it je akce s nejmenší pravděpodobností pit
pitt bude nejvýše 1/N (kdyby měly všechny akce stejnou pravděpodobnost)
nastavíme ℓitt=0 a ℓit=1 každému i=it
pitt≤1/N⟹ℓAt≥1−1/N⟹LAT≥T(1−1/N)
algoritmus B∈Aall, který v kroku t zvolí akci it s pravděpodobností 1 bude mít kumulativní ztrátu LBT=0
Algorithm: Greedy algorithm
budeme vybírat akci s nejmenší kumulativní ztrátou Lit−1 v kroku t−1
nejprve zvolíme první akci (s pravděpodobností 1), pak vždycky vezmeme první z akcí s minimální kumulativní ztrátou (s pravděpodobností 1)
St−1 … množina akcí s minimální kumulativní ztrátou (v kroku t−1)
tvrzení: pro libovolnou posloupnost ztrátových vektorů z {0,1}N bude kumulativní ztráta hladového (greedy) algoritmu v čase T∈N splňovat LGreedyT≤N⋅LminT+(N−1)
přičemž LminT=min{LiT∣i∈X}
důkaz
v každém kroku t
pokud hladový algoritmus prodělá ztrátu 1 a Lmint se nezvýší, pak alespoň jedna akce zmizí z St v dalším kroku
to se stane nejvýše N-krát a pak se Lmint zvýší o 1
tedy mezi dvěma zvýšeními Lmint prodělá algoritmus ztrátu nejvýše N
z toho vyplývá LGreedyT≤N⋅LminT+N−∣ST∣≤N⋅LminT+(N−1)
to je docela slabé, protože A tak může být přibližně N-krát horší než nejlepší akce
ale žádný deterministický algoritmus nemůže být o moc lepší
Algorithm: Randomized greedy algorithm
přidáme „náhodu“ – uniformně náhodně vybereme z těch s minimální kumulativní ztrátou
p1 tentokrát nastavíme na (1/N,…,1/N)
v dalších krocích vždy všem prvkům množiny St−1 nastavíme pravděpodobnost na 1/∣St−1∣ (ostatní budou mít nulovou)
St−1 … množina akcí s minimální kumulativní ztrátou (v kroku t−1)
tvrzení: pro libovolnou posloupnost ztrátových vektorů z {0,1}N bude kumulativní ztráta LRGT randomizovaného hladového algoritmu v čase T∈N splňovat LRGT≤(1+lnN)⋅LminT+lnN
důkaz
postupujeme jako v důkazu hladového algoritmu
jakou ztrátu algoritmus nasbírá mezi zvýšeními Lmint?
pokud se St v určitém kroku (který je někde mezi dvěma zvýšeními Lmint) zmenší o k, znamená to, že ztráta algoritmu v tomhle kroku byla k/n′ (kde n′ je původní velikost St)
zjevně k/n′=k⋅n′1≤kn′1+n′−11+⋯+n′−k+11
mezi dvěma zvýšeními Lmint se St může zmenšit z velikosti N na 1, takže za tu dobu může být ztráta nejvýše N1+N−11+⋯+11≤1+lnN
proto LRGT≤(1+lnN)⋅LminT+N1+N−11+⋯+∣ST∣+11≤(1+lnN)⋅LminT+lnN
Algorithm: Polynomial weights algorithm
vstup: množina akcí X={1,…,N}, T∈N a η∈(0,21]
výstup: pravděpodobnostní distribuce pt pro každé t∈{1,…,T}
algoritmus
∀i∈X:wi1←1
p1←(1/N,…,1/N)
pro t=2,…,T
∀i∈X:wit←wit−1(1−ηℓit−1)
∀i∈X:pit←wit/Wt
kde Wt=∑jwjt (normalizační konstanta)
věta
pro η∈(0,21], libovolnou posloupnost ztrátových vektorů z [−1,1]N a libovolnou akci k∈X platí, že kumulativní ztráta LPWT algoritmu polynomiálních vah splňuje LPWT≤LkT+ηQkT+lnN/η
přičemž QkT=∑t=1T(ℓkt)2
zejména pokud T≥4lnN, pak volbou η=lnN/T a přihlédnutím k QkT≤T získáme LPWT≤LminT+2TlnN
důkaz
pro krok t máme ℓPWt=∑i=1Nwitℓit/Wt
váha wit každé akce i se násobí (1−ηℓit−1) v kroku t, proto Wt+1=Wt−∑i=1Nηwitℓit=Wt(1−ηℓPWt)
jelikož Fex⊆Fsw a Fin⊆Fsw, tak external a internal regret budou nutně menší nebo rovny swap regretu
Theorem: Reduction from external regret to swap regret
máme algoritmus polynomiálních vah, který umí zajistit libovolně malý external regret
pro swap regret takový algoritmus zkonstruujeme pomocí black-box redukce
definice: R-external regret algoritmus A garantuje, že pro každou posloupnost ztrátových vektorů (ℓt)t=1t a pro každou akci j∈X budeme mít LAT=∑tℓAt≤∑tℓjt+R=LjT+R
věta
pro každý R-external regret algoritmus A existuje algoritmus M=M(A) takový, že pro každé F:X→X a T∈N platí LMT≤LM,FT+NR
tedy že swap regret algoritmu M je nejvýše NR
důkaz
mějme N kopií algoritmu A, označíme je jako A1,…,AN
algoritmus M konstruujeme jako jejich kombinaci
v každém kroku k každý Ai vrací pravděpodobností rozdělení qit
přičemž qi,jt je pravděpodobnost, kterou Ai přiřazuje akci j∈X
nechť Qt je matice N×N taková, že Qijt=qi,jt
zkonstruujeme pravděpodobnostní rozdělení pt takové, že (pt)T=(pt)TQt
tedy ∀j:pjt=∑i=1Npitqi,jt
lze ukázat, že pt existuje a lze ho efektivně spočítat (je to stacionární distribuce markovského řetězce)
díky téhle volbě můžeme volbu akcí uvažovat dvěma způsoby – buď akci zvolíme s pravděpodobností pjt nebo nejprve zvolíme algoritmus Ai s pravděpodobností pit a pak použijeme algoritmus Ai, aby zvolil j s pravděpodobností qi,jt
když získáme ztrátový vektor ℓt, pro každé i∈X přiřadíme algoritmu Ai ztrátový vektor pitℓt
tak Ai prodělá ztrátu (pitℓt)⋅qit=pit(qit⋅ℓt)
jelikož Ai je R-external regret algoritmus, platí ∀j∈X:∑t=1Tpit(qit⋅ℓt)≤∑tpitℓjt+R
když posčítáme ztráty všech algoritmů v kroku t, dostaneme celkovou ztrátu ∑i=1Npit(qit⋅ℓt)=(pt)TQtℓt
díky volbě pt máme (pt)T=(pt)TQt
proto se celková ztráta v kroku t rovná pt⋅ℓt, což je reálná ztráta algoritmu M v kroku t
nyní posčítáme za celou dobu běhu (z R-external regret) přes všechny algoritmy LMT=i=1∑Nt=1∑Tpit(qit⋅ℓt)≤i=1∑Nt=1∑TpitℓF(i)t+NR=LM,FT+NR
kde F je libovolná funkce F:X→X (v definici R-external regret je tam libovolné j)
použijeme-li algoritmus polynomiálních vah jako A, získáme algoritmus se swap regret nejvýše O(NTlogN)
tedy průměrný swap regret jde k nule s T→∞
Algorithm: No-swap-regret dynamics
jako no-regret, akorát je tam swap regret
vstup: G=(P,A,C) hra n hráčů, T∈N a ε>0
výstup: pravděpodobnostní rozdělení pit na Ai pro každé i∈P a t∈{1,…,T}
pro každý krok t=1,…,T
každý hráč i∈P nezávisle vybere smíšenou strategii pit pomocí algoritmu s průměrným swap regretem nejvýše ε (kde akce odpovídají čistým strategiím)
každý hráč i∈P získá ztrátový vektor ℓit, kde ℓit(ai)=Ea−it∼p−it[Ci(ai;a−it)] pro rozdělení p−it=∏j=ipjt
Theorem: Converging to CE
věta
mějme libovolné G=(P,A,C), ε>0 a T=T(ε)∈N
pokud má po T krocích no-swap-regret dynamics každý hráč i∈P time-averaged expected regret nejvýše ε, pak p je ε-CE
přičemž pt=∏i=1npit (součin přes všechny hráče) a p=T1∑t=1Tpt
pravé strany jsou time-averaged expected costs hráče i (když hraje podle algoritmu nebo když hraje vždycky F(ai) místo ai)
každý hráč má regret nejvýše ε, proto T1t∑Ea∼pt[Ci(a)]≤T1t∑Ea∼pt[Ci(F(ai);a−i)]+ε
to ověřuje ε-CE podmínku pro p=T1∑t=1Tpt
Games in extensive form
Definition: Extensive game, (im)perfect-information game
hra v rozšířené (explicitní) formě
odpovídá orientovanému stromu, jehož vrcholy představují stavy hry
strom kóduje celou historii hry
hra začíná v kořeni stromu a končí v listu, kde každý hráč získá výplatu
hrana stromu odpovídá tomu, že se jeden hráč přesouvá z jednoho stavu hry do druhého
vrcholy, které nejsou listy, se označují jako rozhodovací uzly
tahy, které hráč v daném stavu může provést, odpovídají výstupním hranám daného rozhodovacího uzlu
hra s dokonalou informací – všichni hráči vědí, v jakém jsou stavu
hra s nedokonalou informací – hráči mají jenom částečnou znalost stavu hry
rozdělíme rozhodovací uzly na informační množiny
uzly v jedné informační množině patří stejnému hráči a mají stejné tahy
hráč ví, v jaké informační množině se nachází, ale nedokáže určit, v jakém je uzlu
množina informačních množin hráče i se označuje jako Hi
pro h∈Hi nechť Ch je množina možných tahů z h
Definition: Strategies in extensive games
čistá (pure) strategie hráče i
přesný popis, jakou akci zvolit v každé informační množině hráče i
pomocí čistých strategií můžeme hru G v rozšířené formě převést na hru G′ v normálním tvaru – prostě uděláme tabulku všech čistých strategií
smíšená (mixed) strategie
smíšené strategie G odpovídají smíšeným strategiím G′
je to pravděpodobnostní distribuce nad vektory
behaviorální strategie hráče i
je to pravděpodobnostní distribuce na Ch pro každé h∈Hi
je to vektor pravděpodobnostních distribucí
hráč se v každé informační množině rozhoduje nezávisle
na rozdíl od smíšené strategie se hráč může rozhodnout různě, když do h přijde vícekrát
ve hře s dokonalou pamětí hráč nemůže do jedné h přijít vícekrát, proto tam pojmy smíšené a behaviorální strategie splývají (viz Kuhnova věta)
Definition: Games of perfect recall, Kuhn’s theorem
posloupnost σi(t) tahů hráče i do uzlu t je posloupnost jeho tahů (nehledě na tahy ostatních hráčů) po jedinečné cestě z kořene stromu do t
prázdná posloupnost se značí ∅
hráč i má dokonalou paměť (perfect recall), právě když pro každé h∈Hi a libovolné t,t′∈h platí σi(t)=σi(t′)
v takovém případě používáme σh k označení jedinečné posloupnosti vedoucí do libovolného uzlu t∈h
kdyby rovnost neplatila a hráč by si pamatoval historii, byl by schopen rozhodnout, zda se nachází v t nebo v t′
podle definice dané hry jsou ale t,t′ ve stejné informační množině, tedy je hráč nedovede rozlišit
proto zjevně nemá dokonalou paměť – je to ale vlastnost designu hry, ne hráče
G je hra s dokonalou pamětí, pokud má každý hráč dokonalou paměť
žádný hráč nezapomíná informace, které znal o svých dosavadních tazích
každá hra s dokonalou informací je hra s dokonalou pamětí
Kuhnova věta
ve hře s dokonalou pamětí může být každá smíšená strategie daného hráče nahrazena ekvivalentní behaviorální strategií a libovolná behaviorální strategie může být nahrazena ekvivalentní smíšenou strategií
Definition: Sequence form
sekvenční forma (reprezentace posloupnostmi) je čtveřice (P,S,u,C)
P … množina n hráčů
S=(S1,…,Sn), kde Si je množina posloupností i-tého hráče
u=(u1,…,un), kde ui:S→R je výplatní funkce i-tého hráče
C=(C1,…,Cn), kde Ci je množina lineárních omezujících podmínek nad realizačními parvděpodobnostmi i-tého hráče
posloupnosti Si
libovolná posloupnost z Si je buď prázdná ∅, nebo je jednoznačně určena posledním tahem c v informační množině h
Si={∅}∪{σhc∣h∈Hi,c∈Ch}
∣Si∣=1+∑h∈Hi∣Ch∣, což je lineární vzhledem k velikosti stromu
výplatní funkce ui
mějme hráče i a posloupnosti σ=(σ1,…,σn)∈S
pokud se po tom, co každý hráč j zahraje svou sekvenci σj, hra dostane do listu ℓ, rovná se výplatní funkce ui(σ) hodnotě ui(ℓ)
jinak ui(σ)=0
výplatní funkce lze popisovat (řídkými) maticemi – pokud jsou hráči dva, používají se matice A,B
realizační plán behaviorální strategie βi pro hráče i je zobrazení x:Si→[0,1], definované jako x(σi)=∏c∈σiβi(c)
realizační plán je pravděpodobnost, že hráč zahraje určitou posloupnost, pokud hraje danou behaviorální strategii
ekvivalentně můžeme použít lineární rovnice
realizační plán hráče i je zobrazení x:Si→[0,1] splňující x(∅)=1 a ∑c∈Chx(σhc)=x(σh) pro každé h∈Hi
Ci je množina těchto rovnic
omezující podmínky Ci
lze je zapsat jako Ex=e,x≥0
E má 1+∣Hi∣ řádků
první řádek rovnice Ex=e odpovídá x(∅)=1
další řádky odpovídají −x(σh)+∑c∈Chx(σhc)=0 pro každé h∈Hi
realizační plán lze převést na behaviorální strategii tak, že βi(h,c)=x(σh)x(σhc)
Theorem: Using the sequence form to find NE
mohli bychom G převést na G′ v normálním tvaru a použít Lemke–Howsonův algoritmus, ale počet akcí v G′ je exponenciální vůči velikosti G, takže by byl počet kroků algoritmu dvojitě exponenciální → proto jsme si definovali sekvenční formu
best responses
pro pevný realizační plán y druhého hráče spočítáme best response x prvního hráče
x je řešení lineárního programu P
maxxTAy za podmínek Ex=e,x≥0
duál D má tvar
mineTu za podmínky ETu≥Ay
hry s nulovým součtem
použijeme větu o dualitě na P a D, tím dostaneme lineární program pro nalezení NE
druhý hráč chce minimalizovat xTAy, což se z duality rovná eTu, pokud první hráč maximalizuje svůj payoff xTAy
věta: Nashova ekvilibria hry dvou hráčů v rozšířené formě s nulovým součtem s dokonalou pamětí jsou řešení lineárního programu
minu,yeTu za podmínek Fy=f,ETu−Ay≥0,y≥0
duál k tomuto programu najde realizační plán x pro prvního hráče
počet nenulových položek v maticích E,F,A je lineární vůči velikosti stromu, takže lineární programy lze vyřešit v polynomiálním čase vůči velikosti hry → to je exponenciální zlepšení
hry dvou hráčů
věta: dvojice (x,y) realizačních plánů ve hře dvou hráčů v extenzivní formě s dokonalou pamětí je Nashovo ekvilibrium, právě když existují vektory u,v takové, že xT(ETu−Ay)=0,Ex=e,x≥0,ETu−Ay≥0,yT(FTv−BTx)=0Fy=f,y≥0FTv−BTx≥0
to není lineární program, ale problém lineární komplementarity (linear complementarity problem, LCP)
lze ho řešit pomocí Lemkeho algoritmu, který má exponenciálně mnoho kroků, ale je exponenciálně rychlejší, než kdybychom použili Lemke–Howsonův algoritmus na indukované hře v normálním tvaru
Mechanism design
Definition: Single item auction
v jednopoložkové aukci nabízí prodejce jeden kus zboží n zájemcům
každý zájemce i má svou tajnou valuaci vi, kterou je ochoten zaplatit za zboží
každý zájemce prodejci tajně sdělí svou nabídku (bid) bi
prodejce se rozhodne, který zájemce (jestli nějaký) obdrží zboží a jakou bude muset zaplatit prodejní cenu p
pokud zájemce (bidder) prohraje aukci, jeho užitek ui je nulový, pokud vyhraje aukci, jeho užitek se rovná ui=vi−p
chceme navrhnout mechanismus, který zajistí, že přidělení položky zájemci nemůže být strategicky manipulováno
Definition: Dominant strategy, social surplus, awesome auction
dominantní strategie zájemce i je strategie, která maximalizuje jeho užitek nehledě na to, co dělají ostatní zájemci
sociální zisk (social surplus) je ∑i=1nvixi, kde xi je indikátor toho, zda zájemce i vyhrál
chceme, aby naše aukce byla úžasná, tedy aby garantovala:
DSIC (dominant-strategy incentive compatible)
dominantní strategie každého zájemce je bidovat pravdivě (zvolit bi=vi)
užitek každého pravdivě bidujícího zájemce bude vždy nezáporný
maximalizaci sociálního zisku – pokud zájemci bidují pravdivě
výpočetní efektivitu – aukce by měla jít „spočítat“ v polynomiálním čase
proč to chceme?
DSIC – aby mohli zájemci snadno určit bid a aby mohl prodejce při práci s výsledkem aukce předpokládat, že zájemci bidovali pravdivě
sociální zisk – jenom DSIC by nám nestačilo, chceme identifikovat zájemce s největší valuací
výpočetní efektivita je prostě praktická
Theorem: Vickrey’s auction is awesome
DSIC
uvažujme hráče i
dokážeme, že jeho užitek je maximalizován pro bi=vi
nechť B=maxj∈{1,…,n}∖{i}bj
pokud bi<B, pak i prohrává a jeho užitek je 0
pokud bi≥B, pak i vyhrává a získá užitek vi−B
pokud vi<B, pak může získat nejvýše max{0,vi−B}=0
pokud vi≥B, pak může získat nejvýše max{0,vi−B}=vi−B≥0
těchto užitků dosáhne, pokud biduje pravdivě
sociální zisk – pokud všichni bidují pravdivě, vyhraje hráč s největší valuací
efektivita – aukce běží v lineárním čase
Definition: Single parameter environment
n zájemců, každý má soukromou valuaci vi, což je hodnota „za jednotku zboží“
alokační pravidlo x pro jednoparametrové prostředí je implementovatelné, pokud existuje platební pravidlo p takové, že (x,p) je DSIC
alokační pravidlo „dej položku zájemci s nejvyšší nabídkou“ je v jednopoložkových aukcích implementovatelné, protože platební pravidlo „ať zaplatí druhou nejvyšší cenu“ zajišťuje DSIC
alokační pravidlo x je monotónní, pokud pro každého zájemce i a všechny nabídky ostatních zájemců b−i je alokace xi(z;b−i) hráči i neklesající vzhledem k jeho nabídce z
alokační pravidlo „dej položku zájemci s nejvyšší nabídkou“ je monotónní, alokační pravidlo „dej položku zájemci s druhou nejvyšší nabídkou“ už není
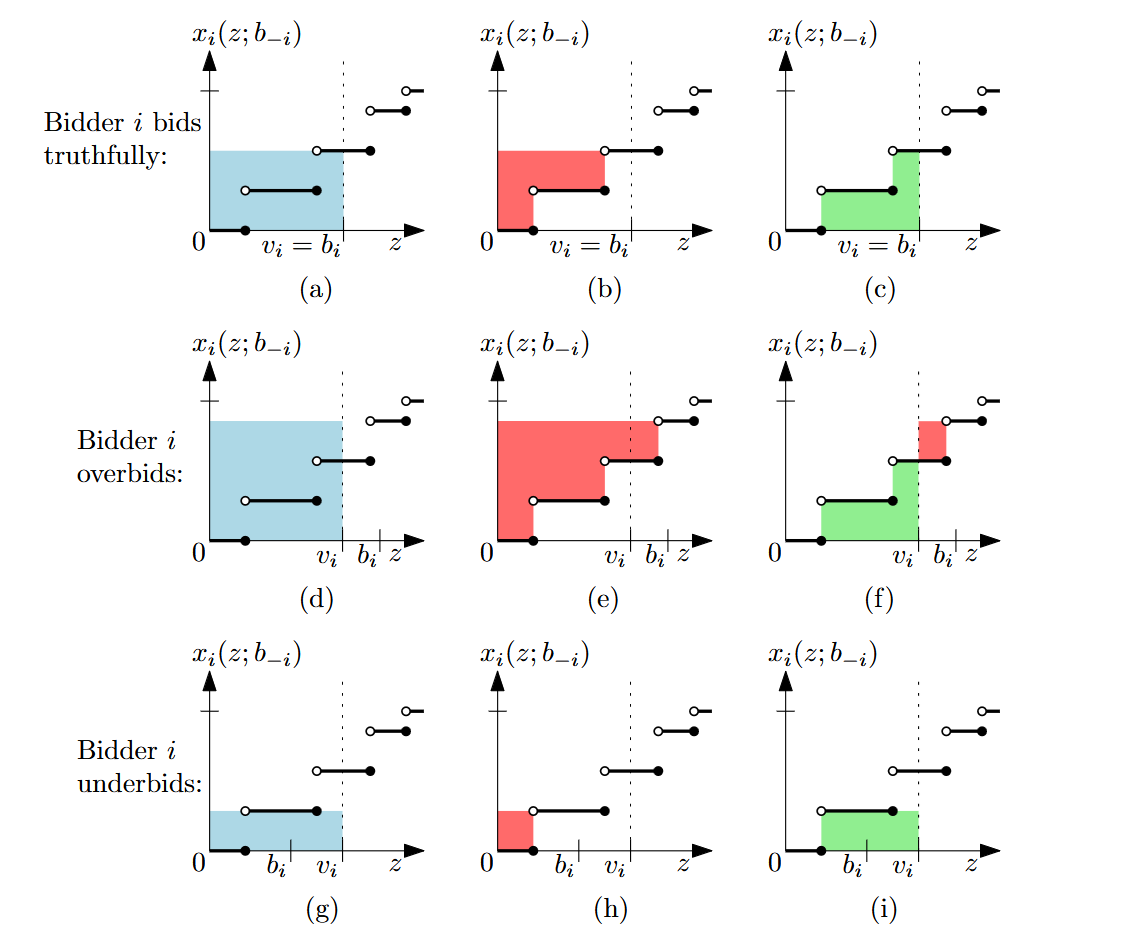
Theorem: Myerson’s lemma
Myersonovo lemma: v jednoparametrovém prostředí platí následující tři výroky
alokační pravidlo je implementovatelné, právě když je monotónní
pokud je alokační pravidlo x monotónní, pak existuje unikátní platební pravidlo p takové, že mechanismus (x,p) je DSIC
za předpokladu, že bi=0⟹pi(b)=0
platební pravidlo p je ∀i:pi(bi;b−i)=∫0biz⋅dzdxi(z;b−i) dz
důkaz
nechť x je alokační pravidlo a p je platební pravidlo takové, že (x,p) je DSIC
dokážeme všechny tři výroky naráz pomocí chytrého prohození
DSIC vlastnost říká, že ∀z:ui(z;b−i)=vi⋅xi(z;b−i)−pi(z;b−i)≤vi⋅xi(vi;b−i)−pi(vi;b−i)
mějme dvě nabídky y,z takové, že 0≤y<z
zájemce i může mít soukromou valuaci z a nepravdivě bidovat y
dosadíme do DSIC: ui(y;b−i)=z⋅xi(y;b−i)−pi(y;b−i)≤z⋅xi(z;b−i)−pi(z;b−i)=ui(z;b−i)
taky by to mohlo být naopak, že by zájemce přestřelil svou valuaci
když dáme tyhle nerovnosti dohromady, získáme payment difference sandwich
z⋅(xi(y;b−i)−xi(z;b−i))
≤pi(y;b−i)−pi(z;b−i)
≤y⋅(xi(y;b−i)−xi(z;b−i))
takže z⋅α≤y⋅α, přičemž y<z
proto α=xi(y;b−i)−xi(z;b−i) musí být menší nebo rovno nule
tudíž xi(y;b−i)≤xi(z;b−i)
proto pokud je (x,p) DSIC, pak je x monotónní
dále budeme předpokládat, že je x monotónní
zafixujeme i,b−i, takže xi,pi budou funkce z
budeme předpokládat, že xi je piecewise konstantní
takže se skládá z konečného počtu intervalů se „skoky“ mezi nimi
velikost skoku funkce xi v bodě t označíme jako jump(f,t)
zafixujeme z v payment difference sendviči a budeme y přibližovat k z (zespodu)
pokud xi nemá skok v z, obě strany se vynulují
pokud jump(xi,z)=h>0, obě strany půjdou k z⋅h
tedy má-li (x,p) být DISC, musí pro každé z platit následující omezující podmínka funkce p
jump(pi,z)=z⋅jump(xi,z)
zkombinujeme-li tuhle podmínku s původní podmínkou pi(0;b−i)=0, získáme vzorec pi(bi;b−i)=j=1∑ℓzj⋅jump(xi(∙;b−i),zj)
kde z1,…,zℓ jsou zlomy alokační funkce xi(∙;b−i) v intervalu [0,bi]
tenhle argument by se dal zobecnit pro obecné monotónní funkce xi, ale k tomu bychom potřebovali matematickou analýzu
je potřeba ukázat, že pokud je x monotónní, pak je (x,p) opravdu DSIC
ukážeme to pro piecewise konstantní funkce, ale fungovalo by to i obecně
platba pi(bi;b−i) se zjevně rovná ploše nalevo od křivky xi(∙;b−i) v intervalu [0,bi]
připomeňme, že užitek ui(bi;b−i)=vi⋅xi(bi;b−i)−pi(bi;b−i)
tedy užitek odpovídá rozdílu obdélníku „valuace × alokováno“ a platby (tedy plochy nalevo od křivky)
DSIC nahlédneme rozborem případů (viz obrázek, jeho autorem je Martin Balko)
Applications of mechanism design
Definition: Bayesian model
součástí bayesovského modelu jsou
jednoparametrové prostředí (x,p)
pravděpodobnostní distribuce F1,…,Fn
Fi … distribuce určující soukromou valuaci i tého hráče
support Fi je obsažen v [0,vmax]
Fi má hustotní funkci fi
jednotlivé Fi jsou nezávislé, ale ne nutně stejné
distribuce F1,…,Fn jsou známy návrháři mechanismu, zájemci je neznají, ale ani je znát nepotřebují, neboť uvažujeme pouze DSIC aukce a oni mají dominantní strategie
cílem je maximalizovat střední hodnotu zisku (revenue) ∑i=1npi(v)
přičemž středí hodnotu počítáme podle distribucí valuací hráčů
to se obvykle dělá tak, že zvolíme minimální cenu
té se říká monopoly price
Theorem: Maximizing expected revenue
věta
nechť (x,p) je DSIC mechanismus v jednoparametrovém prostředí tvořící bayesovský model s n zájemci a distribucemi F1,…,Fn, nechť F=F1×⋯×Fn
pak Ev∼F[i=1∑npi(v)]=Ev∼F[i=1∑nφi(vi)⋅xi(v)]
kde φi(vi)=vi−fi(vi)1−Fi(vi) je virtuální valuace zájemce i
fi … hustota rozdělení Fi
Fi … distribuční funkce (CDF) rozdělení Fi
poznámky
tedy bychom místo maximalizace (našeho) zisku mohli maximalizovat virtuální sociální zisk
virtuální valuace může být i záporná, závisí jenom na vi a Fi, ne na parametrech ostatních hráčů
jakási intuice pro virtuální valuaci
vi … maximální zisk, který můžeme získat od zájemce
fi(vi)1−Fi(vi) … ztráta způsobená tím, že vi neznáme
důkaz
(x,p) je DSIC, takže budeme předpokládat bi=vi pro každého zájemce i
podle Myersonova lemmatu pi(bi;b−i)=∫0biz⋅dzdxi(z;b−i) dz
druhý člen přepíšeme na ∫0vmax(z−fi(z)1−Fi(z))xi(z;v−i)fi(z) dz
což se rovná ∫0vmaxφi(z)xi(z;v−i)fi(z) dz
takže E[pi(vi;v−i)]=E[φi(vi)⋅xi(vi;v−i)]
z linearity střední hodnoty dostaneme požadovanou rovnost
Theorem: Vickrey with reserve price is optimal
tvrzení
nechť F je regulární pravděpodobnostní rozdělení s hustotou f a valuací φ a nechť F1,…,Fn jsou nezávislé pravděpodobnostní rozdělení na valuacích n zájemců taková, že F=F1=⋯=Fn (a tedy φ=φ1=⋯=φn)
pak Vickreyho aukce s rezervní cenou φ−1(0) maximalizuje střední hodnotu zisku
poznámky
F je regulární, pokud φ(v) je ostře rostoucí podle v
Vickreyho aukce s rezervní cenou r
položka se přidělí zájemci s nejvyšší nabídkou, pokud tato nabídka je větší nebo rovna r
pokud jsou všechny nabídky menší než r, nikdo položku nezíská
vítěz musí zaplatit druhou nejvyšší nabídku nebo r
důkaz
podle předchozí věty budeme maximalizovat střední hodnotu virtuálního sociálního zisku
položku dáme zájemci s nejvyšší virtuální valuací
pokud mají všichni zápornou virtuální valuaci, nedáme ji nikomu
z regularity F je φ ostře rostoucí → alokační pravidlo je monotónní → z Myersonova lemmatu máme DSIC aukci (x,p)
Theorem: The Bulow–Klemperer theorem
věta
nechť F je regulární pravděpodobnostní rozdělení
pak Ev1,…,vn+1∼F[Rev(VAn+1)]≥Ev1,…,vn∼F[Rev(OPTF,n)]
kde Rev(VAn+1) je zisk z Vickreyho aukce s n+1 zájemci bez rezervy
tedy nezávisí na F
a Rev(OPTF,n) je zisk z optimální aukce pro F s n zájemci
tedy Vickreyho aukce s rezervou φ−1(0)
závisí na F
důkaz
budeme uvažovat aukci A s n+1 zájemci
bude simulovat OPTF,n na zájemcích 1,…,n
pokud položka nebyla nikomu přidělena, dáme ji zdarma zájemci n+1
takže A z definice vždy přidělí položku a střední hodnota zisku se rovná optimální aukci na n zájemcích
budeme chtít ukázat, že Vickreyho aukce maximalizuje střední hodnotu zisku přes všechny aukce, které přidělí položku
uvažujme optimální aukci (maximalizující zisk), která vždy přidělí položku
taková aukce ji vždy dá zájemci s nejvyšší virtuální valuací
z regularity a rovnosti distribucí plyne, že to bude rovněž zájemce s nejvyšší valuací
takovému zájemci ji dá právě Vickreyho aukce VAn+1
tedy Vickreyho aukce má střední hodnotu zisku aspoň takovou jako libovolná aukce, která vždycky přidělí položku (což je třeba A)
E[Rev(VAn+1)]≥E[Rev(A)]=E[Rev(OPTF,n)]
důsledek
střední hodnota zisku z VAn je aspoň nn−1násobek střední hodnoty zisku z OPTF,n
lze to dokázat podobně jako BK větu, zkonstruujeme aukci, kde budeme jednoho hráče ignorovat (pravděpodobnost, že by ji vyhrál je n1=nn−1 → zisk bude přibližně tolikrát menší)
Definition: Knapsack auction
každý z n zájemců má veřejně známou velikost wi≥0 a soukromou valuaci vi≥0
prodejce má kapacitu W≥0
přípustná množina X se skládá z vektorů (x1,…,xn)∈{0,1}n takových, že ∑i=1nxiwi≤W
xi je indikátor toho, že zájemce i vyhrál
jak zkonstruovat úžasný mechanismus?
zvolíme alokaci x(b) tak, abychom maximalizovali ∑ibixi, tak by se při pravdivém bidování maximalizoval sociální zisk
alokační pravidlo je monotónní, proto nám Myersonovo lemma dá p takové, že (x,p) je DSIC
třetí podmínku úžasných aukcí ale nesplníme, protože x řeší NP-těžký problém batohu
co s tím?
kolidují nám druhá a třetí podmínka
to vyřešíme tak, že tu druhou trochu uvolníme, čímž získáme polynomiální algoritmus
použijeme FPTAS
Theorem: 2-approximation for knapsack auctions
hladové alokační pravidlo
předpokládáme, že ∀i:wi≤W
nechť jsou zájemci seřazeni tak, že w1b1≥⋯≥wnbn
nejprve se budeme snažit v tomto pořadí „batoh“ naplnit co nejvíce – dokud se tam zájemci vejdou → tak získáme možné řešení
vrátíme buď nalezené řešení nebo zájemce s největší nabídkou – podle toho, z čeho bude větší sociální zisk
věta: pokud jsou nabídky pravdivé (podle valuace), sociální zisk hladového alokačního pravidla je aspoň polovina maximálního možného sociálního zisku
důkaz
uvažujme relaxaci problému, kde můžeme použít zlomek zájemce
hladové pravidlo upravíme tak, že použijeme kousek zájemce, který už by se nám nevešel
tak určitě najdeme optimální řešení, protože jsme si zájemce seřadili podle „hustoty“ – libovolné jiné řešení by bylo horší (formálnější důkaz ve skriptech)
vybrané zájemce si označíme 1,…,k, přičemž z k-tého jsme použili jenom kousek
několik pozorování
sociální zisk z prvního kroku hladového pravidla (nezlomkového) je ∑i=1k−1vi
sociální zisk z druhého kroku je aspoň vk (vybíráme ze maximální vi ze zájemců, které jsme nepoužili, vk patří do této množiny)
(∑i=1k−1vi)+vk> optimum
výsledný sociální zisk bude max{vk,∑i=1k−1vi}
to bude nutně aspoň polovina optima (to vyplývá z pozorování – celek se nedá rozdělit na dvě části menší než polovina)
Definition: Multi-parameter mechanism design
n zájemců
konečná množina Ω výsledků
každý zájemce i má soukromou valuaci vi(ω)≥0 pro každý výsledek ω∈Ω
každý zájemce i odevzdá své nabídky bi(ω)≥0 pro každou ω∈Ω
našim cílem je navrhnout algoritmus, který vybere výsledek ω∈Ω, aby maximalizoval sociální zisk ∑ivi(ω)
Theorem: VCG mechanism
věta: v každém prostředí multi-parameter mechanism designu existuje DSIC mechanismus maximalizující sociální zisk
idea důkazu
jakou ztrátu sociálního zisku způsobuje i-tý zájemce ostatním?
třeba v jednopoložkových aukcích způsobuje vítěz ostatním ztrátu rovnou druhé nejvyšší nabídce
definujeme platby tak, aby se zájemci museli zajímat o ostatní
alokační pravidlo bude x(b)=argmaxω∈Ω∑i=1nbi(ω)
platební vzorec bude pi(b)=ω∈Ωmax⎩⎨⎧j=1j=i∑nbj(ω)⎭⎬⎫−j=1j=i∑nbj(ω∗)
přičemž ω∗=x(b), tedy výsledek vybraný naším alokačním pravidlem
důkaz
předpokládejme, že zájemci budou bidovat pravdivě → jaký výsledek zvolit?
maximalizujeme sociální zisk, takže definujeme alokační pravidlo jako x(b)=argmaxω∈Ω∑i=1nbi(ω)
teď zajistíme, aby měli zájemci motivaci bidovat pravdivě (DSIC) – zvolíme vhodné platební pravidlo
„social surplus ostatních v aukci bez i“ − „social surplus ostatních v této aukci“
tedy vlastně „o kolik si ostatní pohoršili účastí i“
lze ukázat, že 0≤pi(b)≤bi(ω∗), takže pravdiví zájemci mají garantovaný nezáporný užitek
zafixujeme i a nabídky ostatních zájemců b−i
pokud x(b)=ω∗ pak se užitek i-tého zájemce rovná vi(ω∗)−pi(b)
což se rovná vi(ω∗)+j=i∑bj(ω∗)−ω∈Ωmax⎩⎨⎧j=i∑bj(ω)⎭⎬⎫
pravý člen je nezávislý na bi, takže zájemce i musí maximalizovat levý člen, pokud chce maximalizovat svůj užitek
zájemce i ale nemůže přímo ovlivnit ω∗, jelikož ho volí mechanismus tak, aby byl součet nabídek maximální
zájemce i chce, aby mechanismus vybral argmaxω{vi(ω)+∑j=ibj(ω)}
pokud i biduje pravdivě, tak to přesně odpovídá naší volbě x, takže pravdivé bidování maximalizuje utilitu i
Theorem: Revelation principle
DSIC můžeme rozdělit na dvě části
každý hráč má dominantní strategii
dominantní strategie je přímé odhalení valuace vi
dává smysl zbavit se druhé části?
ne, důležitá je ta první
druhou část dostaneme zdarma
věta: pro každý multi-parameter mechanismus M, v němž má každý zájemce dominantní strategii nehledě na jeho soukromou valuaci, existuje ekvivalentní mechanismus M′, kde má každý zájemce dominantní strategii, která přímo odhaluje jeho valuaci
důkaz
použijeme simulační argument
pro každého zájemce i mějme jeho valuace vi(ω)ω∈Ω
pro každého zájemce i ať si(vi(ω)ω) je jeho dominantní strategie v mechanismu M
zkonstruujeme M′
M′ přijme zapečetěné nabídky b1(ω)ω∈Ω,…,bn(ω)ω∈Ω od všech zájemců
M′ odešle nabídky s1(b1(ω)ω∈Ω),…,sn(bn(ω)ω∈Ω) do mechanismu M
M′ vrátí stejný výsledek jako M
kdyby zájemce i do M′ odevzdal jiné nabídky než vi(ω)ω, hrozilo by, že bude hrát jinou strategii než si(vi(ω)ω), což by mu mohlo jedině snížit užitek
proto je přímé odhalení valuací dominantní strategie v M′
příklad
uvažujme jednopoložkovou aukci, kde prodávající přijme nabídky (b1,…,bn) a následně provede Vickreyho aukci na nabídkách (2b1,…,2bn)
dominantní strategie je zde nabídnout polovinu své hodnoty
z důkazu věty vyplývá, že bychom mohli zkonstruovat M′, který bude nabídky hráčů půlit → pro tento M′ už by bylo dominantní strategií bidovat pravdivě
Survey questions
Survey: Nash equilibria
Normal-form games
Normal-form game
Strategies
Expected payoff
Five basic games
Nash equilibrium
Best response
Nash equilibrium
Nash’s Theorem
Pareto optimality
ε-Nash equilibrium
Zero-sum games
Zero-sum game and its representation
Worst-case optimal strategies
Worst-case optimal strategies and NE
The Duality Theorem
The Minimax Theorem
Modern proof of the Minimax Theorem
Bimatrix games
Bimatrix game, nondegenerate bimatrix game
Best response condition
Support enumeration
Best response polyhedra, best response polytope
NE and Best response polyhedra/polytope
Vertex enumeration
Lemke–Howson algorithm
Computational complexity of NASH
Problems from PPAD
Survey: Correlated equilibria
Correlated equilibrium (CE)
Properties of correlated equilibria
Polynomial weights algorithm
No-regret dynamics
Coarse correlated equilibrium (CCE)
Converging to CCE
Internal and swap regret
Reduction from external regret to swap regret
No-swap-regret dynamics
Converging to CE
Survey: Regret minimization
Regret minimization model
External regret
External regret as a suitable metric
Greedy algorithm
Randomized greedy algorithm
Polynomial weights algorithm
No-regret dynamics
Modern proof of the Minimax Theorem
Coarse correlated equilibrium (CCE)
Converging to CCE
Internal and swap regret
Reduction from external regret to swap regret
No-swap-regret dynamics
Converging to CE
Survey: Games in extensive form
Extensive game, (im)perfect-information game
Strategies in extensive games
Games of perfect recall, Kuhn’s theorem
Sequence form
Using the sequence form to find NE
Survey: Mechanism design
Single item auction
Dominant strategy, social surplus, awesome auction