this dir | view | cards | source | edit | dark
top
Principy počítačů
- https://slama.dev/poznamky/principy-pocitacu/
- písemná zkouška, 10 otázek, každá za jeden bod, potřebujeme polovinu na úspěšné složení zkoušky, časový limit 4 hodiny, zkouší se s toho, co se probere na přednáškách, dostaneme ukázku (loňskou písemku)
- self-assessment úlohy – dostaneme ke každé přednášce sadu
- za nějaké odevzdané úlohy můžeme dostat desetinu bodu ke zkoušce, až něco přes dva body budeme moci získat, týdenní deadliny
- hodnocení úloh bude až dodatečně, pokud bychom ty body potřebovali
- zadávání a odevzdávání úloh do MS Teams
- videozáznamy nám pošle
- důležité je pochopit, proč věci fungují tak, jak fungují – nemusíme se učit všechno nazpaměť, ale musíme umět termíny
- nemusíme se hlásit, když se na něco budeme chtít zeptat
1. přednáška
- Harvardská architektura počítače
- CPU – procesor, vykonává příkazy
- kódová paměť (code memory) – uložení informací o příkazech
- komunikační linka – umožňuje, aby procesor četl data z paměti
- v základním počítači CPU nemusí zapisovat do kódové paměti, do ní se zapisuje nějak z venku
- datová paměť (data memory) – CPU z ní čte a zapisuje do ní data
- data se ukládají do proměnných
- k procesoru jsou dále připojena vstupně-výstupní zařízení – I/O, periferie
- matematik Charles Babbage vymyslel koncept mechanického počítače – Analytical Engine (v roce 1837), byl plně programovatelný, Turing complete
- jeho přítelkyně Ada Lovelace napsala manuál k tomuto počítači
- vydala publikaci, kde vyslovila myšlenku kódování libovolných dat (textů a multimédií) pomocí čísel
- budeme se zabývat tím, jak v počítači reprezentovat čísla (všechna ostatní data na ně můžeme převést)
- informace (data) → čísla → celá čísla → nezáporná celá čísla
- zaznamenáme libovolné číslo od nuly do milionu
- nula je 0 V, miliion je 5 V, všechno ostatní mezi tím
- problém je při vysílání, každý vodič má odpor
- změna odporu při teplotě
- kvůli vlastnostem vodičů vzniká elektromagnetický šum
- analogový přenos
- posledním zjednodušením je přenášení čísel nula/jedna
- této číslici budeme říkat bit (binary digit), b
- stanovíme hranici napětí, všechny hodnoty nad ní budeme interpretovat jako jedničku, hodnoty pod ní jako nulu
- digitální přenos – přenos číslic
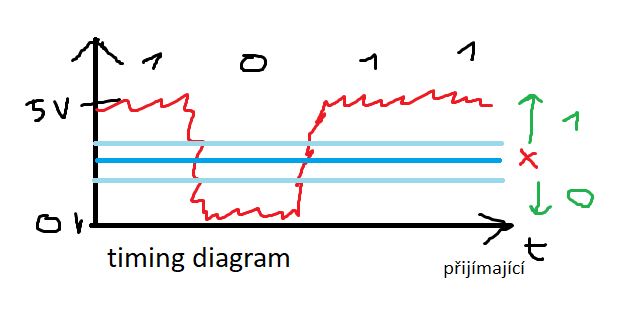
- sériový digitální přenos
- záleží na pořadí číslic – přijímající a vysílající se musí dohodnout
- označíme si bit s nejnižší váhou – Least Significant bit (LSb)
- bitu s nejvyšší váhou budeme říkat Most Significant bit (MSb)
- stanovíme bit order – MSb-first nebo LSb-first
- mocniny dvojky
- 16 = 2^4
- 256 = 2^8
- 1024 = 2^10
- 4096 = 2^12
- 65536 = 2^16
- cca 10^6 = 2^20
- cca 16 000 000 = 2^24
- cca 4 200 000 000 = 2^32
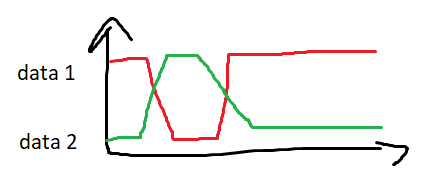
- diferenciální přenos
- data 1 – data 2
- >0 = 1
- <0 = 0
- řešení problému se dvěma jedničkama / dlouhou jedničkou
- pevná délka bitu
- definuje se přenosová rychlost
- v bitech za sekundu (bits per second, bps)
- jednotka baud [bód] (symbol za sekundu) – obvykle budeme uvažovat x baud = x bps, ale jeden symbol může obsahovat více bitů
2. přednáška
- vodiče
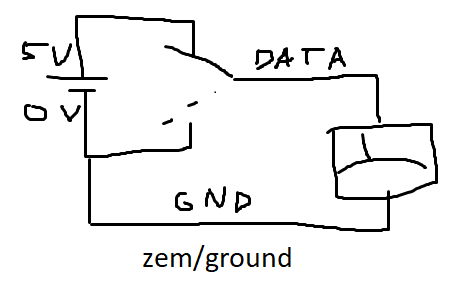
- klasický způsob přenosu (není diferenciální) – data a GND
- diferenciální – data+, data–
- přijímač se na signál kouká přibližně v polovině bitů
- přenosová rychlost zajišťuje intervaly čtení, je ale nutné zajistit začátek čtení (synchronizaci hodin, "tikání")
- musíme si odlišit stav, kdy se nic nepřenáší, od začátku přenosu
- idle stav – nic nepřenášíme
- floating stav / stav s vysokou impedancí / Hi-Z = stav, kdy je obvod rozpojený, ale vodič indukuje náhodnou hodnotu
- 3-stavová logika – funguje na lince, kde umíme rozlišit floating stav, nulu a jedničku
- floating stav bychom mohli požadovat za idle stav
- my ale chceme fungovat na 2-stavové logice (lince)
- můžeme definovat idle stav jako nulu
- začátek přenosu označíme pomocí start condition – rising edge (rostoucí hrana)
- definujeme si, že na začátku přenosu bude start bit (nebo nějaký určitý počet start bitů)
- potom začíná přenos užitečných bitů (datových bitů / data bits)
- data bits se do obrázku značí podobně jako diferenciální přenos, ale znamenají něco jiného (jde o obecné značení bitů, jaké je možné posílat)
- může se stát, že se nám vysílání a příjem bitů posune
- proto definujeme maximální délku přenosu – max X → const X (definujeme konstatní maximální délku)
- N bitů celkem rozdělíme po X bitech
- výrobci se shodli, že se přenos bude uskutečňovat po 8 bitech
- 8 bitů = 1 byte (B)
- 8 bitů = 1 octet (existuje několik málo zařízení, která mají jinou velikost bytu, proto je obecně správnější používat označení octet)
- po X bitech (obvykle osmi, ale může být i více bytů) – stop condition (falling edge, klesající hrana), stop bity, idle stav, start condition, start bity, ...
- takhle navržená linka přenáší 20 % času technická data (8 data bits, 1 start bit, 1 stop bit) – 20% overhead
- přenosová rychlost bps (bits per second) – počítají se data bits
- synchronizaci je možné řešit i pomocí hodinového signálu (clock) – linka vysílající střídavě nuly a jedničky, jednička značí čas čtení (zajišťuje synchronizaci přijímače a vysílače)
- vodiče
- data, GND, clock
- diferenciální – data1, data2, clock, GND, (clock1, clock2) (?)
- přenosová rychlost by mohla být definovaná rychlostí tikání hodinového signálu
- hodinový signál může generovat vysílající – určité nevýhody
- hodinový signál může generovat centrální oscilátor
- cyklus (cycle/takt) hodinového signálu definuje přenosovou rychlost
- lépe se detekují hrany signálu – můžeme si definovat, že rostoucí hrany hodinového signálu definují momenty čtení
- abychom zrychlili přenos, můžeme používat obě hrany hodinového signálu (rostoucí i klesající) – označení DDR (double data rate)
- co když je hodinový vodič kratší než datový vodič?
- můžeme se vykašlat na hodiny a synchronizovat se jiným způsobem – vždy jen v určitých (delších) intervalech
- mohli bychom se synchronizovat pomocí hran, ale museli bychom mít jistotu, že se v datech dostatečně často střídají jedničky a nuly – to ale nemusí vždy platit
- na každých osm bitů bychom mohli poslat 10 bitů
- ke každé kombinaci osmi bitů bychom mohli namapovat kombinaci 10 bitů, které jsou dostatečně "hezké" – dostatečně často se tam střídají jedničky a nuly
- přijímač i vysílač má mapovací tabulku
- tento způsob synchronizace se nazývá clock recovery, používá se např. v USB
- vodiče v USB: 5 V, GND (tyto dva slouží k napájení připojeného zařízení), data+, data– (tyto dva zajišťují přenos dat)
- zbylé dva způsoby synchronizace přenosu používají linky I²C (pomocí hodinového signálu) a RS-232 (pomocí start a stop bitů)
- linky simplex a duplex
- přenos jedním směrem – simplex
- přenos oběma směry – duplex
- half-duplex – strany se musejí domlouvat, kdo zrovna posílá
- full-duplex – nezávisle data přenášíme oběma směry → řešení pomocí dvou zcela nezávislých simplexních linek
- např. RS-232
- Rx – přijímající vodič (receiver)
- Tx – vysílající vodič (transmitter)
- dále se definují out-of-band signály
- přenášejí se tam informace nezávisle
- obvykle přenášejí konstatní nulu nebo jedničku – signál platí/neplatí
- běžné kódování – 0 = nepravda, 1 = pravda
- power-out signál
- někdy dává smysl to definovat obráceně – 0 = platí, 1 = neplatí → inverzní logika
- obvyklá značení inverzní logiky na signálu SIG: SIG (s čárou nad textem), #SIG, /SIG, !SIG, SIG (bílé písmo na černém pozadí)
- hodiny reálného času – RTC
- chceme, aby nám zařízení poslalo tři informace – den, měsíc a rok
- třeba 9 bitů na den, 5 bitů na měsíc, 7 bitů na rok
- musíme si definovat, jak bude která informace dlouhá
- komunikační protokol/formát
- jeden logický blok dat = packet (tento packet by měl 21 bitů)
- musíme se dohodnout na MSb-first / LSb-first
- délka packetu nemusí být pevná, délka packetu může být definovaná uvnitř packetu
- řadič (controller) – zařízení, které zajišťuje ovládání linky (procesor → linka → řadič → linka → myš)
- uvnitř je registr daného zařízení – data register
- komunikace s řadičem z programu – musím mu říct, jak má interpretovat změny na datovém vodiči, který jde z myši
- pomocí pyserial → serial → Serial
- nastavení řadiče (config register)
- status register – ukládá informaci, v jakém stavu je datový registr (např. 0 = no change, 1 = new byte in data register)
- operace přečtení data registru zaznamená do status registru nulu
- funkce, které komunikují se zařízeními, mají často nějaký timeout, aby čekání na data nebylo nekonečné
3. přednáška
- řadič řeší komunikaci programu s myší a překlad ze sedmibitových na osmibitové bajty
- sériovou myš také potřebujeme nějak napájet
- běžně v USB konektoru jsou 4 piny, z toho dvoje data, zem a napájení
- kvůli kompatibilitě se sériová myš připojovala pomocí RS-232 linky
- RS-232 nemá napájecí konektor, ale pouze out of band signály
- sériová myš je tedy napájená pomocí out of band signálů RTS a DTR nastavených na hodnotu 1
- v řadiči je control register (modem control register) – pro každý out of band signál je tam jeden bit, který má hodnotu 0 (false) nebo 1 (true)
- jak resetovat myš? stačí nastavit signály RTS a DTR na nulu → myš se po chvíli vypne → můžeme myš opět zapnout
- (nemusíme si pamatovat, že to jsou zrovna RTS a DTR)
- po zapnutí myš pošle inicializační packet (init packet) – není přesně definován
- po zapnutí myši tedy čekáme na X (třeba 1024) bajtů
- čekáme pomocí funkce .read(n), tato funkce je ale blokující
- ideální by byla neblokující funkce
- řešením je nastavení timeoutu
- potřebujeme být schopni stisknout klávesu na klávesnici a začít dělat něco jiného
- input() – blokující funkce
- keyboard.is_pressed('<key>') → True/False – neblokující funkce
- přijímání dat z myši
- bity jsou zprava doleva seřazeny 0–7 (podle zápisu čísla ve dvojkové soustavě)
- myš posílá 7 bitů, takže MSb je pro ni bit č. 7
- stisknutí levého tlačítka → packet 96 0 0 0
- 96 = 64 + 32 = 2^6 + 2^5 → 01 10 00 00 (01 LR YY XX)
- co dělat s informací 738201600
- šestnáctková/hexadecimální/hexa/hex soustava
- značení čísla v šestnáctkové soustavě: 23,23h,0x23,23_{16},23_{hex}$
- značení čísla v desítkové soustavě: 2310,23dec
- pro uložení jedné číslice v šestnáctkové soustavě využijeme 4 bity
- 1 bajt zaberou dvě šestnáctkové číslice
- nuly na začátku čísla = leading zeros
- 73820160010= $2C001000 → 2C 00 10 00 → nenulové bity jsou pouze na některých místech
- bity 29, 27, 26 a 12 jsou jedna
- čísla zadané v Pythonu v desítkové soustavě se ukládají ve dvojkové soustavě
- proměnou lze uložit v šestnáctkové soustavě, Python ji opět uloží ve dvojkové soustavě → není rozdíl mezi 35 a 0x23
- funkce print(a) vezme dvojkovou proměnnou a převede ji na string
- znaky stringu jsou uloženy pomocí osmibitových čísel
- funkce hex(a) vrací zápis čísla v šestnáctkové soustavě
- funkce format(a, '04X') doplní číslo o leading zeros na 4 číslice
- modifikovaný kód
- packet 60 00 00 00 → první byte 01 10 00 00
- proč má první byte v 6. bitu jedničku?
- abychom ho poznali od ostatních tří bytů a nedošlo ke špatné synchronizaci snímání komunikace myši
- bitové operace – obvykle dva argumenty (binární operace)
- n-bitová operace (např. osmibitová – podle délky každého ze dvou vstupů a délky výstupu)
- 8-bit operace – na vstupu dvě osmibitová čísla, na výstupu jedno osmibitové číslo
- operace vždy vezme dva bity na stejné pozici, nějakým mechanismem je zkombinuje a výsledek uloží do bitu na téže pozici
- operace or: 1010 | 1100 = 1110
- můžeme kombinovat hodnotu a příkaz – jednička v příkazu znamená natvrdo nastavit výsledek na jedna, nula v příkazu znamená zkopírovat hodnotu do výsledku
- nastavení bitu (na jedna) se označuje jako set
- operace and: 1010 & 1100 = 1000
- když je příkaz nula → nastav natvrdo nulu
- když je příkaz jedna → zachovej hodnotu
- vymazání bitu – clear (to 0)
- bitová negace not ~
- ~ 1010 = 0101
- v Pythonu funguje jinak
- operace xor (eor)
- exkluzivní or
- 1010 ^ 1100 = 0110
- selektivní flip (not)
- když je jednička, převrať hodnotu
- když je nula, zkopíruj hodnotu
- jak zjistit, jestli je levé tlačítko stisknuté
- použijeme bitovou masku
- na ?? L? ?? ?? použijeme masku 00 10 00 00 a operaci and
- dostaneme buď 00 00 00 00 → tlačítko není stisknuté, nebo 00 10 00 00 → tlačítko je stisknuté
- B1 (byte 1) & 0x20 = 0x20 → levé tlačítko je stisknuté
- pohyb myši
- kvůli přesnosti chceme použít 8 bitů, v jednom bytu je ale jenom 6 volných míst (máme 7bitový byte a bit č. 6 určuje pořadí bytu)
- informaci tedy rozdělíme 1. a 2. bytu
- B1 & 0x03
- B2 & 0x3F
- chceme ze dvou čísel 000000XX a 00XXXXXX dostat XXXXXXXX
- použijeme magii a převedeme 000000XX → XX000000
- XX000000 | 00XXXXXX = XXXXXXXX
4. přednáška
- potřebujeme magickou operaci, která nám umožní posunout bity
- = bitové posuny (bitwise shifts)
- posun doleva (shift left) – SHL (<<)
- a << x → b
- a – hodnota, se kterou chceme pracovat (n-bitové číslo)
- b – výsledek operace (n-bitové číslo)
- x – o kolik bitů se má posunout (celé číslo)
- posun k MSb!
- příklad
- 4-bit 1101 (vlevo MSb, vpravo LSb)
- SHL 1 → výsledek: 1010
- o jedničku úplně vlevo jsme přišli, vpravo přibyla nula
- SHL 3 → výsledek: 1000
- SHL n → výsledek: 0000
- posun doprava (shift right) – SHR (>>)
- a >> x → b
- funguje podobně jako SHL, akorát opačně
- posun k LSb
- rotace doleva (rotate left) – ROL
- 1101 ROL 3 → 1110 (vysunuté bity nerušíme, ale ve stejném pořadí zasuneme z druhé strany)
- výsledkem ROL n je identita
- rotace doprava – ROR
- rotace Python nepodporuje
- potřebujeme rozlišit posun myši nahoru a doleva → záporná čísla ve formě jedniček a nul
- bezznaménková čísla (unsigned)
- znaménková čísla (singed)
- signed magnitude – 1 bit určuje znaménko, ostatní bity hodnotu čísla
- z hlediska kompatibility je výhodné umístit znaménkový bit na místo MSb, přičemž 1 určuje záporné číslo, 0 kladné
- při počítání pouze s nezápornými čísly ztrácíme polovinu rozsahu, takže se v takovém případě může hodit použít bezznaménková čísla
- každý procesor podporuje operace pro bezznaménková čísla
- můžeme libovolně přecházet mezi interpretací čísla jako znaménkového a bezznaménkového
- nefunguje nám bezznaménkové porovnání na porovnávání záporných čísel (ani sčítání apod.)
- jedničkový doplněk (ones' complement)
- kladná čísla jsou zaznamenaná stejně jako unsigned
- záporná jsou zaznamenaná znegovaně
- jak udělat z kladného čísla záporné?
- u signed magnitude pomocí operace XOR
- u jedničkového doplňku negací
- problém s nulou
- máme dvě nuly – kladnou a zápornou
- u jedničkového doplňku můžeme negovat a přičíst jedničku → dostaneme zpátky nulu
- dvojkový doplněk (two's complement)
- kladná čísla jako unsigned
- záporná čísla jsou negace absolutní hodnoty plus 1
- rozsah –128 až 127
- nefunguje porovnání mezi kladnými a zápornými čísly – procesor musí podporovat znaménkové porovnání
- MSb určuje znaménko
- nejběžněji používaná implementace záporných čísel
- Python ke každému číslu ukládá počet platných bitů, ukládá je jako znaménková čísla
- jejich rozsah je prakticky neomezený
- při posunech (<< a >>) nikdy nepřijdu o číslice – Python si čísla před operací zvětší odpovídajícím způsobem
- funkce bit_length() vrací bitovou délku čísla (bez znaménkového bitu)
- knihovna numpy nám umožní vyrábět proměnné pevně daných typů (uint8, uint16, int8, …)
- čísla intX jsou znaménková, takže tam mj. funguje porovnání
- funkce type(x) nám vrátí typ čísla
- převod 8-bit čísla na 4-bit
- operace truncation, přebytečné bity se zahodí – v podstatě xmod2n
- u čísel blízko nuly funguje dobře, u vzdálenějších čísel získáváme modulo
- převod 4-bit čísla na 8-bit
- bezznaménkové rozšíření (zero extension) – na začátek se přidají čtyři nuly, nefunguje pro znaménková čísla
- znaménkové rozšíření (signed extension) – rozkopíruje znaménkovou číslici do nových bitů, nefunguje pro bezznaménková čísla
- v Pythonu se bezznaménkové rozšíření používá jenom při převodu mezi dvěma bezznaménkovými čísly, jinak se používá znaménkové rozšíření
5. přednáška
- Harvardská architektura – CPU čte z kódové paměti, čte z datové paměti a zapisuje do datové paměti
- datové paměti můžeme říkat operační paměť (operating memory)
- periferie komunikují s CPU jednosměrně nebo oběma směry (monitor posílá informace o rozlišení, klávesnice přijímá informace o rozsvícení diod)
- zařízení
- master – řídí přenos (řídící – řídí komunikaci)
- slave – poslouchá (řízený)
- při komunikaci procesoru s pamětí je procesor master, paměť je slave
- když data proudí směrem master → slave, tak jde o zápis, opačným směrem je to čtení
- typický procesor funguje jenom jako master – abychom toto pravidlo neporušili, používáme řadič
- řadič je potřeba u myši, u klávesnice tato potřeba obvykle není, protože se chová jako slave (uvnitř má vlastní registr)
- komunikační linka point-to-point – z procesoru by muselo vést mnoho vstupů/výstupů
- chceme komunikační linku, která umožňuje více vstupů/výstupů – multidrop/bus/sběrnice (linka se sběrnicovou topologií)
- nákres – z CPU vedou dvě sběrnice, na jedné jsou připojené paměti, na druhé perfiferie (myš za řadičem), CPU je master, všechno ostatní slave
- adresa (address) zařízení na sběrnici (typicky 0 až n)
- v příkazu v programu pro procesor budou dvě informace – chci komunikovat se zařízením X na sběrnici Y
- adresy zařízení musí být unikátní v rámci jedné sběrnice
- rozsah adres (address space)
- máme X bitový adresový prostor → platné adresy jsou 0 až 2x−1
- někdy i master musí mít vlastní adresu?
- zařízení je připojené na sběrnici
- má Rx a Tx – může přijímat i vysílat data
- je tam víc zařízení, zkusíme se obejít bez floating stavu
- k lince připojíme 5 voltů přes rezistor s velkým odporem (pull-up rezistor, kdyby tam byla nula voltů, tak by to bylo pull-down rezistor)
- když není žádné zařízení připojené k lince, tak je stav linky 1 (protože je tam těch pět voltů za rezistorem)
- zařízení je připojené, ale nedělá nic → nepřipojí se ke sběrnici´→ stav linky je 1
- zařízení je připojené a vysílá jedničku → nepřipojí se ke sběrnici → stav linky je 1
- zařízení je připojené a vysílá nulu → připojí se (na malém rezistoru v zařízení na Tx je 0 V) → stav linky je 0
| D1 |
D2 |
bus |
| x |
x |
1 |
| x |
1 |
1 |
| x |
0 |
0 |
| 1 |
1 |
1 |
| 1 |
0 |
0 |
| 0 |
1 |
0 |
| 0 |
0 |
0 |
- spodní čtyři řádky implementují AND
- I2C – Inter Integrated Circuit
- vodič SDA – sériová data
- vodič SCL – sériové hodiny
- oba vodiče posílají digitální signál
- oba vodiče jsou připojené na pull-up rezistor
- napájecí napětí se označuje jako VDD nebo VCC
- pod 30 % VDD se považuje za nulu, nad 70 % za jedničku
- multimaster – různá zařízení můžou být master
- existují i singlemaster sběrnice – např. USB
- musíme rozeznat idle stav od přenosu
- SCL tiká jenom během přenosu, generuje ho master
- dvě jedničky (na SDA i SCL) znamenají idle stav
- na lince existují nepovolené stavy – např. změna stavu na SDA při jedničce na SCL – toho využijeme jako START a STOP condition
- START condition = sestupná hrana na SDA při jedničce na SCL
- STOP condition = vzestupná hrana na SDA při jedničce na SCL
- sběrnice má 9-bitové byty: 8 data bit + 1 control bit
- kontrolní bit (acknowledgement/potvrzovací/ACK bit)
- (acknowledgement = ACK × negative acknowledgement = NACK/NAK)
- první byte vždycky posílá master, slave ho potvrzuje kontrolním bitem
- další byty posílá vysílající a přijímající potvrzuje (pokud přijímající přestane potvrzovat, vyhodnotí se to jako NAK)
|
B1 |
a1 |
B2 |
a2 |
B3 |
a3 |
|
| write |
M |
S |
M |
S |
M |
S |
NAK |
| read |
M |
S |
S |
M |
S |
M |
NAK |
- MSb-first komunikace
- série bytů tvoří packet, ten se dělí na overhead (I2C control) a payload (device specific – požadovaná data)
- I2C sestává ze slave address (7-bit) a bitu určujícího směr přenosu R/Wˉ
- read = 1, write = 0
- devátý control bit má obrácenou logiku – 0 = ACK, 1 = NAK (typicky pokud tam slave není)
- když slave nestíhá, tak může v hodinovém signálu generovat nulu → master ví, že nemůže posílat další data – tomu se říká clock stretching / hold clock low
Ambient Light Sensor (ALS)
- ve smartphonu určuje intenzitu okolního světla a podle toho se určuje intenzita podsvícení
- v datasheetu najdeme informace o fungování
- zařízení má čtyři piny – VDD (napájení), GND (zem), SDA (data), SCL (hodiny)
- v zařízení bude senzor a logika
- součástí logiky je counter register – zajišťuje počítání intenzity světla
- měření v intervalech (na začátku měření se counter vynuluje)
- příkazy start integration a stop integration
- command register (cmd reg)
- při extrémních hodnotách lze softwarově prodloužit/zkrátit dobu měření, abychom vůbec něco naměřili (to zajišťuje procesor zařízení)
- counter register = ADC register (analog digital converter)
- existuje také DAC (digital analog converter) – opačný proces, z digitálního signálu se generuje např. analogová intenzita světla
- v ALS má 2 byty – z toho 15 datových bitů a jeden valid bit
- připojení na sběrnici zajišťuje bus interface – skrze něj máme jako programátoři přístup k registrům
- write-only register (W/O)
- read-only register (R/O)
- read-write register (R/W) – v ALS nenajdeme
- v případě ALS bude „zápis“ znamenat zápis do W/O cmd registru a „čtení“ bude znamenat čtení z R/O counter registru
- adresa zařízení na sběrnici je pevně daná výrobcem – hardwired/zadrátovaná, v tomto případě je to $29 – na jednu sběrnici tedy nemůžu připojit dvě stejná zařízení, protože by měla stejnou adresu
- u vícebytových čísel se rozlišuje LSB (byte s LSb) a MSB (byte s MSb)
- kromě bit order se určuje byte order
6. přednáška
- nechceme pokaždé přenášet celý obsah paměti
- každému bytu přiřadíme adresu (n-bit unsigned), definujeme si paměťový adresový prostor
- u 256 bytové paměti budeme mít 8-bitový adresový prostor (0 až 255 …28−1)
- můžeme mít 200 bytovou paměť s 8-bitovým adresovým prostorem (podobně můžeme mít 256 bytovou paměť s 16-bitovým adresovým prostorem)
- použití většího prostoru znamená možnost budoucího rozšiřování paměti
- nechceme pracovat s velkými čísly – místo bajtů použijeme kilobajty
- 1 kB = 1024 B, 1 MB = 1024 kB, … (pro přehlednost se používají zkratky KiB, MiB, GiB → kibibyte, …)
- výrobci disků používají 1 kB = 1 000 B
- pro uložení adresy bytu v KiB potřebujeme 10-bitovou adresu, pro adresování KiB v MiB také 10-bit, takže u GiB adresujeme konkrétní byte pomocí 30-bitové adresy
- u adres bytů v KiB potřebujeme 10-bitovou adresu, ale binárně to vychází na 16-bit, takže takto můžeme adresovat 64kB médium
- u 24-bitového prostoru 16 MB
- u 32-bitového prostoru 4 GB
- bity v registru řadiče: 1 bit → 1 latch (4–6 tranzistorů)
- nejrychlejší způsob uložení do paměti
- SRAM (Random Access Memory)
- charakteristické vlastnosti
- umožňuje volbu adresy
- jednotná rychlost (uniform speed)
- dnešní paměti RAM tohle většinou nemají
- nejrychlejší přístup – sekvenční (postupný přístup k rostoucím adresám)
- nejpomalejší – random (nelze předvídat, kam budeme přistupovat)
- sekvenční přístup ke klesajícím adresám – záleží na konkrétní paměti
- další vlastnost tohoto typu paměti je schopnost čtení a zápisu
- typická vlastnost pamětí RAM – jsou volatile (po vypnutí napájení se ztrácí obsah)
- kódová paměť počítače by tedy měla být non-volatile
- kapacita – v jednotkách B, kB, MB
- nevýhody – cena, rozměry
- paměti DRAM
- základní vlastnosti odpovídají SRAM
- bit se ukládá pomocí 1 tranzistoru a 1 kondenzátoru
- D v názvu znamená dynamic
- nabité kondenzátory se postupně vybíjejí do vybitých
- cca po milisekundě se náboje vyrovnávají
- refresh paměti – součástka se podívá na náboje a obnovuje jejich původní hodnoty (v tuto chvíli do paměti nemůže nikdo přistupovat)
- DRAM je tedy pomalejší než SRAM
- přenosová rychlost – nejvíce ovlivňuje sekvenční přenosy, u SRAM 10 až 100 GB/s, u DRAM 1 až 10 GB/s
- access time – u SRAM jednotky ns, u DRAM desítky ns
- u naší 256 bytové paměti kódujeme adresu na I2C pomocí tří proměnlivých bitů
- pevný začátek adresy, za něj se přidávají hodnoty tří bitů
- 1 slovo (1 word) – jednotka přenosu/zpracování
- je pro nás důležitá velikost slova
- čím větší slovo, tím rychlejší přenos
- n-bit device (paměť)
- n-bit CPU (procesor umí pracovat s n-bitovými čísly)
- adresa z pohledu CPU – adresa bajtu
- u 16-bitové paměti tvoří dva bajty jedno slovo – používá adresy slov
- podobně u 32-bitové paměti
- adresy tedy musíme překládat
- nesprávný význam slova: slovo = 16 bitů
- dvojslovo (double word / DWORD / DW) – dvojnásobek slova (často 32 bitů)
- čtyřslovo (quad word / QWORD / QW) – čtyřnásobek slova (v praxi často 64 bitů)
- obsah naší paměti
- bus interface – I2C sběrnice, tři připojené vodiče určují adresu paměti
- adresový registr – velikost odpovídá velikosti adresového prostoru
- datový registr – velikost odpovídá velikosti slova
- na I2C: 100 kHz → 100 000 b/s → 12 500 B/s
- na jeden bajt se přenese 3×9 bitů
- → 3 708 B/s
- můžeme předpokládat, že po zapsání bytu budeme chtít zapsat na ten za ním, tedy adresový registr inkrementujeme o 1
- takhle dostaneme (u nekonečného přenosu) rychlost 11 109 B/s
- 1 write tx (transakce) = 1 I2C tx
- 1 read tx = 2 I2C tx (1 write do addr reg + 1 read z data reg)
- obecně jsou ale typické paměti RAM rychlejší na čtení než zápis
- registrový adresový prostor zařízení – když má zařízení více registrů, ke kterým chceme přistupovat
7. přednáška
- Harvardská architektura
- CPU
- data memory – implementujeme pomocí RAM (y-bit)
- code memory – sice problém s volatilitou, ale taky implemementujeme pomocí RAM (x-bit)
- sběrnice s připojenými řadiči a zařízeními
- packety pro komunikaci s paměťmi generuje procesor
- instrukce procesoru
- každý procesor má od výroby definovanou instrukční sadu (instruction set), kterou podporuje
- jedna instrukce je posloupnost N bajtů v kódové paměti (délky se můžou, ale nemusí lišit – podle procesoru)
- v paměti jsou uloženy za sebou, procesor je vykonává směrem k vyšším adresám
- procesor si musí pamatovat, kterou instrukci právě vykonává
- k tomu slouží registry procesoru
- nejzákladnější registr obsahuje adresu instrukce, která se právě vykonává – obvykle se mu říká program counter (PC) nebo instruction pointer (IP; přičemž pointer = ukazatel = adresa)
- vícebytová instrukce
- instruction pointer ukazuje na base address (nejnižší adresa z toho rozsahu bytů)
- dává smysl určovat u bajtů, jak jsou daleko od base address – říká se tomu offset (0 u bytu s base address, u dalších bytů 1, 2, 3, …)
- po vykonání instrukce se k IP přičte délka instrukce
- instrukce se obvykle skládá z několika částí
- jednoznačný identifikátor instrukce – opcode (operační kód)
- např. 105 = ADD (+), 106 = SUB (–)
- zbytek tvoří argumenty instrukce
- argumenty můžou být implicitní – např. přičti jedničku, je to napevno dané typem instrukce
- IP je x-bitový, ukazuje do kódové paměti
- proměnné (argumenty) u instrukcí jsou y-bitové, ukazují do datové paměti
- posloupnosti instrukcí se říká strojový kód (machine code)
- program v Pythonu
- uložený jako text – posloupnost bytů (1 byte = 1 znak)
- můžeme mít program – překladač (compiler), který jako vstup přijímá text pythonového programu a jako výstup generuje posloupnost bytů (strojový kód)
- magicky přesuneme výsledek z data memory do code memory a zařídíme, aby ho procesor začal vykonávat
- vytvořit překladač je těžké
- může existovat také interpret (interpreter)
- prochází text programu a zpracovává ho podle sady podmínek ve strojovém kódu
- interpret se píše snáz než překladač
- v programovacím jazyce je proměnná identifikovaná jménem, kdežto ve strojovém kódu adresou
- překladač musí zařídit, aby proměnné alokoval na volných pozicích
- jak do paměti uložit vícebytovou hodnotu
- endianita (endianness)
- viz Gulliverovy cesty
- little endian (LE) – na nejnižší adresu ukládám LSB
- pravidlo LLL (least significant byte, lowest address, little endian)
- big endien (BE) – na nejnižší adresu ukládám MSB
- je důležité ujasnit si endianitu – má ji danou procesor, dnes je nejběžnější LE (některé mobilní procesory jsou BE)
- problém nastává, když použijeme externí zdroj dat – tam musíme endianitu řešit a případně přeházet pořadí bytů
- po síti se data většinou posílají v BE pořadí
- code memory by měla být non-volatile
- nevýhody non-volatile pamětí
- jsou pomalejší
- mají omezený počet zápisů (opotřebovávají se)
- → proto nemůžeme non-volatile paměť použít pro data memory
- je těžké zařídit přemístění programu z data memory do code memory, interpretovat veškerý kód by bylo zase neoptimální → řešením je jiná architektura
- von Neumannova architektura
- operační paměť, kde je obojí – v jedné části kód programu, v jiné části data programu
- zajistíme, aby IP obsahoval adresy z určitého rozsahu a aby adresy proměnných byly zase z jiného rozsahu
- je to hardwarově komplikovanější na implementaci, ale přináší to spoustu výhod
- lze zařídit, aby IP ukazoval na začátek přeloženého programu
- potenciální zranitelnost, pokud útočník do dat určených ke čtení uloží spustitelné byty a zařídí jejich spuštění
- operační paměť bude volatile – RAM
- potřebujeme jiné magické zařízení, které do RAM zkopíruje počáteční program z non-volatile paměti
- historie počítačů (prezentace) – všechny architektury jsou von Neumannovské
- UNIVAC – drahý, pro velké firmy na počítání mezd (byl to sálový počítač, prodalo se jich cca 100)
- Altair 8800 – první malý počítač, pro „matfyzáky“
- Bill Gates a Paul Allen napsali překladač Microsoft BASICu, aby Altair mohla používat širší veřejnost
- Apple I – Steve Wozniak, skvělá architektura
- Steve Jobs mu pomohl marketingově
- někdo vytvořil aplikaci VisiCalc (počítání daní) – killer app
- Atari – hraní her, připojovalo se k televizi, tyto počítače se dostaly do tehdejšího Československa přes železnou oponu
- procesor 6502 (díky ukradení plánů na výrobu procesoru vznikaly československé kopie počítačů)
- všechny procesory do té doby měly von Neumannovu architekturu, byly 8bitové a používaly 16bitový adresový prostor
- 8bitový procesor umožňuje pracovat s 8bitovými čísly
- IBM PC – procesor 8088
- procesor typu x86-16
- 16bitový procesor (uměl zpracovat dvě 16bitová čísla najednou)
- 20bitový adresový prostor – zvládl adresovat 1 MB
- 64 kB RAM
- při zvýšení paměti (koupi nového počítače) se daly používat původní programy – díky tomuto triku se počítače ujaly
- Intel – architektura x86 / IA-32
- 32-bit procesor, 32-bit adresový prostor → až 4 GB
- 2 instrukční sady – jedna 16-bit, druhá 32-bit, dá se mezi nimi přepínat
- AMD – architektura Intel 64 / x64
- 64-bit, 64-bit
- 3 instrukční sady
- základní instrukce – srovnání 6502 a x86
- instrukce skoku – nastavím IP na konkrétní hodnotu (nepodmíněný skok – unconditional jump)
- podmíněný skok (conditional jump) – potřebujeme u if
- řídící struktury (podmínky a cykly) se dají implementovat pomocí těchto dvou skoků
- je těžké pamatovat si instrukce procesoru a psát přímo strojový kód → pro každý procesor se vymyslí tzv. assembler (assembly code)
- je důležité chápat rozdíl mezi textovým zápisem assembleru a samotným strojovým kódem
- při překladu je potřeba složité příkazy rozdělit do jednoduchých
- procesory typicky vyžadují, aby maximálně jeden argument instrukce byl adresa, ostatní argumenty tedy musíme uložit do registru
- registry procesoru
- speciální registr (PC/IP)
- obecné registry – tam uložíme proměnné, abychom je mohli použít jako argumenty instrukce
- a = b + c
- LOAD addr(b) → R1
- ADD R1 + addr(c) → R2
- STORE R2 → addr(a)
- procesory s load/store architekturou jsou omezené tak, že všechny argumenty musí být v registrech (např. architektura MIPS)
- dva typy LOAD
- nahrání konstanty (immediate) – přímá hodnota jako součást instrukce
- nahrání pomocí adresy
- např. pro registr A jsou to instrukce LDA, STA
- instrukce kopírování mezi registry (transfer)
- např. kopírování X → A by se zapsalo jako TXA
- kopírování hodnot mezi bajty v paměti – postupně LDA, STA (pro každý bajt dané hodnoty)
8. přednáška
- registry
- A, X, Y – pomocné registry pro účely programu (u 8-bit procesoru budou 8-bit)
- PC – u 16-bit adresového prostoru bude 16-bit
- P – příznakový registr (flags register)
- příznak (flag) = 1 bit informace
- typické příznaky
- zero – byl výsledek poslední operace roven nule?
(1 = ano, byla nula; 0 = ne, nebyla nula)
- sign/negative – označuje znaménko výsledku poslední operace
(1 = –, 0 = +), čísla se typicky zaznamenávají ve dvojkovém doplňku
- carry – pokud potřebujeme u nějaké operace uložit jeden bit navíc
- instrukce CLC (nastavuje na 0), SEC/STC (nastavuje na 1)
- instrukce můžou mít side-effect – mění určité příznaky
- ke čtení příznaků se typicky používají podmíněné skoky
- dva typy registrové architektury
- obecná registrová architektura … x86
- akumulátorová architektura … 6502
- akumulátor A, většina instrukcí umí pracovat jenom s tím akumulátorem
- místo instrukce NOT se dá použít XOR #$FF (respektive EOR #$FF)
- 8bitové sčítání
- 8-bit vstup A
- 8-bit vstup B
- 1-bit vstup Cin (carry in)
- 8-bit výstup R
- 1-bit výstup Cout (carry out)
- instrukce ADC (add with carry)
- ke carry vstupu a výstupu používá carry příznak
- před začátkem výpočtu je potřeba vynulovat carry příznak
- odčítání
- v 7-bit přesnosti pomocí negace a přičtení jedničky (viz dvojkový doplněk)
- 8-bit rozdíl/subtract – subtract with borrow (SBB) – na x86
- subtract with carry (SBC) – na 6502
- chceme A – X – B
- trik: A – X – B + 256
- borrow je negace carry
- A – X – (1 – C) + 256
- A – X – 1 + C + 256
- A – X + C + 255
- A + (255 – X) + C
- A + NOT(X) + C
- α = NOT X
- A + α + C
- ADC α
- registry x86
- 32-bit: EAX, EBX, ECX, EDX, ESI, EDI, EBP
- 8bitové/16bitové „virtuální“ registry – např. AX, AH, AL
- instrukce x86
- MOV na přesouvání
- ADD (nepřičítá hodnotu carry, jako CLC + ADC)
- SUB
- výpočet r=a+b+e−(c+d)
- na 6502 můžu používat pouze akumulátor, k tomu musím ukládat mezi výpočty do paměti
- na x86 si vystačím s registry
9. přednáška
- taktovací frekvence (clock rate) – dnes v řádu GHz
- 1 takt/cycle
- nejrychlejší instrukce (fast) – procesor je stihne za jeden takt, všechny tyto operace pracují s hodnotami v registrech
- bitové operace (AND, SHL, …)
- ADC/SBB
- pomalé operace (slow) – práce s pamětí
- LOAD/STORE
- operace s implicit load (např. ADC počítající s číslem z paměti)
- pozn.: pokud sčítám 64-bit čísla na 8-bit procesoru, musím provést 8 operací sčítání + nějaké operace load a store
- 6502 má cca 1 MHz
- x86 cca 33 MHz
- procesor má cache, která urychluje přístup k paměti
- sign extension – při rozšíření čísla na víc bytů zachováváme jeho znaménko – u záporných čísel přidáváme jedničky, u kladných nuly
- v Pythonu každé číslo zabírá 4 byty, protože počítače bývají 32-bit (a více)
- v Pythonu ukládám pointer (ukazatel/reference) na objekt s hodnotou, typem, garbage collector ref countem, délkou…
- garbage collector – udržuje si informaci o počtu odkazů na daný objekt, pokud je nula, tak objekt smaže
- v jazycích C/C# může nastat aritmetické přetečení (arithmetic overflow)
- uint8: 255 + 1 = 0
- int8: 127 + 1 = –128
- podtečení … při odčítání
- procesory x86 a x64 mají operace násobení a dělení
- násobení: 1–10 taktů
- dělení: cca 50–100 taktů
- u 6502 je potřeba SW implementace
- shift left funguje jako násobení mocninou dvojky
- x SHL n=(x⋅2n)mod2z
- shift right funguje jako celočíselné dělení mocninou dvojky
- arithmetic shift right – u záporných čísel doplňuje jedničky místo nul
- programovací jazyky implementují různě, v Pythonu SHL + SAR, v C# SHL + SHR (uint) / SAR (int), v Javě SHL (<<) + SAR (>>) + SHR (>>>)
- reprezentace reálných čísel
- 20,625
- fixed-point 8bit
- 20 + 0,625
- 10100,101
- 5.3 nebo 5+3
- není problém s aritmetickými operacemi
- problém u velkých a malých čísel
- reálné číslo reprezentované jako fixed-point na float převedu vydělením n-tou mocninou dvojky
10. přednáška
- floating-point
- normalizovaná
- 1 číslice před desetinnou čárkou
- žádné leading zeros
- bez nuly
- uložíme mantisu (significand) a exponent
- exponent uložíme na stranu MSb, mantisu na stranu LSb
- floating-point se skrytou jedna – využijeme toho, že každé číslo začíná jedničkou (zakázali jsme leading zeros), takže ukládáme až číslice za desetinnou čárkou
- celá signed čísla: reprezentace s posunem (bias)
- např. 8-bit → rozsah 0 až 255
- 255 = nejvyšší kladná hodnota (128)
- 127 = 0
- 0 = nejnižší záporná hodnota (–127)
- ale pokud bychom chtěli víc kladných a míň záporných hodnot, tak se to dá posunout
- pomocí posunu se vyjadřuje znaménko exponentu
- znaménko mantisy se vyjadřuje pomocí znaménkového bitu (MSb)
- taková čísla se nedají sčítat (ale dají se porovnávat) → je potřeba SW nebo HW implementace
- některé procesory mají speciální registry a operace s floating-point čísly
- x86/x64 a dražší ARMy mají podporu, levnější ARMy, 6502 nemají
- standard pro floatová čísla IEEE 754
- single 32-bit – v numpy float32, v C# float
- double 64-bit – v Pythonu float, v numpy float64, v C# double
- během aritmetiky musí dojít k denormalizaci
- 0.1 se nedá zapsat s ukončeným desetinným rozvojem
- nula = samé nuly (až na znaménko) – standard definuje, že se kladná nula rovná záporné nule
- samé jedničky v exponentu a nulová mantisa → kladné/záporné nekonečno
- samé jedničky v exponentu a nenulová mantisa → not a number (NaN)
- ∞/∞= NaN
- jsou dva typy NaN
11. přednáška
- jednočip/microcontroller/\microC/MCU
- SRAM data memory – 256 B, volatile
- CPU + registry
- code memory – non-volatile
- ROM (Read Only Memory)
- PROM (Programmable ROM) – jeden zápis, nekonečno čtení; funguje na základě spálení diod
- EPROM (Erasable PROM) – nekonečno zápisů, nekonečno čtení
- maže se UV zářením, je potřeba nechat to na slunci 20 minut
- EEPROM (Electrically EPROM) – „nekonečno“ zápisů, nekonečno čtení
- flash – „nekonečno“ zápisů, nekonečno čtení
- EEPROM + flash se dnes používají nejčastěji – souhrnný název NVRAM
- EEPROM × flash
- EEPROM – posloupnost bajtů
- flash – bajty ukládá v blocích po 1–16 kB
- EEPROM má sekvenční, random 1 byte a random block čtení průměrně rychlé
- flash má pomalejší random 1 byte, ale rychlejší sekvenční čtení i random block čtení
- zcela nekonečné zápisy nejsou možné, protože elektronům se postupně „přestává chtít ven z komůrek, kde jsou zabedněné“
- takže při běhu programu se používá RAM, do non-volatile paměti se v případě potřeby zapisuje v určitém rozumném intervalu
- ADC (převodník z analogového na digitálního signálu)
- např. uživatelský vstup – potenciometr
- DAC – analogový výstup
- GPIO řadič (General Purpose Input/Output)
- registry ovlivňující, zda jsou piny vstupní/výstupní
- permanentní datové úložiště (mass storage device)
- von Neumannovská architektura
- DRAM – kód + proměnné
- CPU + SRAM
- pevný disk / hard disk drive (HDD)
- magnetický zápis
- dipól – otočený na jednu stranu (podle toho 1 nebo 0)
- dipóly jsou uloženy ve soustředných kružnicích
- jedna kružnice = stopa
- stopy jsou rozdělené na sektory (sektory jsou v podstatě kruhové výseče)
- na jednom sektoru původně 512 B, dnes 4 kB (4096 B, advanced format)
- čtecí hlava
- 7200 RPM (otáček za minutu)
- náhodný přístup v jedné stopě je lepší než sekvenční přístup pozpátku
- hlava se otáčí, aby přistupovala k různým stopám – tomu se říká seek (seek time – doba otočení)
- náhodný přístup mezi stopami je extrémně pomalý
- přístup v řádech ms (jiné paměti se pohybují v řádu ns)
- vhodné pro archivaci
- několik ploten, lze zapisovat z obou stran každé z nich
- všechny hlavy se pohybují najednou
- stopám, které jsou nad sebou, se říká cylinder
- v praxi se čísluje trojicí čísel – cylinder/hlava/sektor
- stopy vzdálenější od středu mohou být rozděleny na více sektorů pro dosažení větší kapacity
- úhlová rychlost je stejná, ale rychlost čtení/zápisu u jednotlivých stop se liší
- CD/DVD/BluRay
- zápis/čtení pomocí laseru
- pomalejší zápis/čtení
- jedna spirální stopa
- Linear Block Addressing
- jakmile dojdou data, přestává čtení – takže lze mít různé tvary CD
- 1 sektor = 2048 B
- řadič DVD
- address register (LBA)
- buffer = 1 sektor
- command register – podle toho, zda chci provádět čtení/zápis
- status register – ready?
- info register – kapacita disku
- potřebuju „magii“, která zajistí přesun dat z řadiče do paměti zařízení
- data register – obsahuje interní address reg., vrací vždy 1 bajt z bufferu
- řadič HDD (HDC = Hard Drive Controller)
- řadič pevných disků se ovládá podobně jako řadič DVD, dostává LBA adresu
- flash paměť s řadičem pevného disku – SSD
- USB fleška: USB řadič → USB kabel → řadič → flash paměť
- jakmile se data nahrají z disku do paměti, jsou uloženy v nějaké posloupnosti adres – první z nich se nazývá bázová
- v Python potřebujeme pole bytů, není rozumné používat seznam, protože každé číslo seznamu by mělo svůj overhead
- chceme na disk ukládat soubory
- pamatujeme si data samotného souboru + metadata
- metadata
- seznam sektorů, kde je soubor uložený (nemusí být přímo za sebou → fragmentace)
- délka v B
- cesta souboru – adresáře (directories, složky/folders) a název souboru
- datum, čas apod.
- metadata → souborový systém (file system)
- kromě zmíněného obsahuje i seznam volných sektorů
- přístup k souborům řeší operační systém
- soubor se otevře (jeho metadata se načtou do cache) → pracuje se s ním → zavře se (aby OS věděl, že ho nemusí držet v paměti)
11,5. přednáška
- pythoní funkce open zavolá funkci operačního systému (OpenFile), která do paměti uloží metadata a vrátí ID souboru, které se uloží v pythoním objektu
- soubor se dá otevřít jako binární (s příznakem b) – výsledný objekt má jiný typ
- na binárním souboru máme funkci read, které zadáme, kolik bytů chceme přečíst
- operační systém si do paměti připraví celý sektor, z něj vrátí požadované bajty
- pythoní objekt si pamatuje aktuální offset
- read posouvá offset o počet čtených bajtů, pokud chceme skočit k aktuálnímu bajtu, můžeme použít funkci seek (tato funkce umožňuje skákat relativně), funkce tell slouží ke zjištění aktuálního offsetu
- pythoní funkce seek nesouvisí se čtecí hlavou
- funkce readline (u textového souboru) vrátí celý řádek ve formě textu
- textový soubor (text file) – všechny bajty souboru se dají interpretovat jako text
- binární soubor (binary file) – pro některé nebo všechny bajty platí, že se nedají interpretovat jako text
- hexdump / hexview
- file format – specifikace, co bajty na konkrétních offsetech v souboru znamenají
- binární soubory často na začátku obsahují metadata (hlavička souboru / header, může být na konci souboru nebo např. před skupinou dat)
- na začátku souboru může být sekvence bytů, která jednoznačně určuje formát (takže lze případně vyloučit, že se jedná o soubor v daném formátu) – magic number / signature
- MIDI soubor – zápis not (není uložen zvuk)
- soubor BMP
- obraz disku
12. + 12,5. přednáška
- reprezentace obrazových dat
- fotka = obdélníkový obrázek
- doba expozice (n-tina sekundy) – za tu dobu se počítá, kam dopadají fotony
- na sítnici oka dopadají fotony – vnímáme nějaký průměr
- fotku můžeme rozdělit na čtverečky – pixely
- potřebujeme označit pixely
- sloupečky (osa x) se číslují od nuly zleva doprava
- řádky (osa y) se číslují od nuly shora dolů
- pixely se obvykle ukládají po řádcích, v rámci řádku zleva doprava
- pixel nemusí mít jeden bajt
- intenzita světla (počet fotonů) může nabývat hodnot 0 až nekonečno
- pixel bude n bitů – bpp (bits per pixel) = bitová hloubka (bit depth)
- nejjednodušší
- jeden bit na pixel
- stanovíme hraniční intenzitu – hodnoty pod ní uložíme jako nula, nad ní jako jedna
- velmi omezená informace
- pro určité zobrazovací technologie (klasický LCD displej) dostačující
- tento princip ukládání nám umožňuje pixely sdružit např. po čtveřicích (tedy snížit rozlišení) a zachycovat odstíny šedé kombinací různého počtu černých a šedých pixelů (tzv. differing)
- https://en.wikipedia.org/wiki/List_of_monochrome_and_RGB_color_formats
- jeden bajt na pixel
- stanovíme dvě meze – spodní (0) a horní (255)
- intenzitu uložíme jako číslo v rozmezí 0 až 255
- meze je potřeba stanovit podle situace
- bylo by hezké zaznamenávat obrázky, kde jsou oba extrémy (a u těchto extrémů ukazovat detaily)
- použijeme floating-point čísla
- HDR (High Definition Range)
- moc se nepoužívá – je těžké takovou fotku zachytit atd.
- chceme barvu
- dívali jsme se jenom na počet fotonů, ne na jejich frekvenci (tedy barvu)
- frekvence může být 0,00… (nenulová) až nekonečno
- obvykle nás zajímá viditelné světlo
- v oku
- tyčinky – monochromatické vidění, velký rozsah
- čípky – barevné vidění, malý rozsah
- tři druhy čípků – jsou citlivé na různé frekvence (červené, zelené, modré)
- barevný kanál → 3 kanály (RGB), nezávislé informace
- 3-bit RGB – za každou barvu uložíme 1 bit
- špatně se dělí osmi, přidáme bit navíc
- 4-bit RGBI – navíc tmavší varianta barvy
- 16-bit RGB
- každou barvu pomocí 3 bitů
- co s posledními bitem?
- dáme ho zelené složce, protože tu lidské oko zvládne nejvíc rozlišovat
- nebo s ním také nemusíme dělat nic (→ 15-bit RGB)
- 24-bit RGB
- 8 bitů na kanál
- hi-color / True Color
- ale máme 32bitové instrukce procesoru
- 32-bit ARGB
- čtvrtý bajt je tzv. alpha kanál
- 255 = neprůhledný pixel
- 0 = zcela průhledný pixel
- metadata obrázku
- počet kanálů
- bitů na pixel/kanál (bitová hloubka)
- šířka v pixelech
- výška v pixelech
- další informace ve formátu EXIF
- jak uložit pixel
- typicky ARGB (A v MSB, B v LSB)
- nebo také RGBA
- navíc záleží na endianitě
- takže existují 4 možnosti: ARGB, RGBA, BGRA, ABGR
- buď je v metadatech informace o pořadí složek, nebo je to ve specifikaci formátu
- rastrový obraz, bitmapa
- formát BMP
- specifický způsob ukládání – zespodu nahoru
- každý řádek je zarovnaný (align) – na konci má padding (nadbytečné bajty bez významu), aby řádky začínaly na místech dělitelných čtyřmi (aby se dobře načítaly)
- textová data
- textový řetězec (string) = posloupnost znaků
- znak
- písmeno
- číslice
- speciální znak
- bílý znak (whitespace)
- řídicí znak
- kódování
- jeden znak → jeden kód
- kód → bitová reprezentace
- pevná délka / proměnná délka
- rasterizace textu
- převod kód → obrázek (znak)
- poznámka: jazyky se ukládají v pořadí, v jakém se čtou
- kódování
- ASCII
- 7bitové (0–127)
- písmena abecedy jsou uloženy za sebou, podobně číslice
- znak nuly nemá kód nula
- mezera má kód 32 (šestnáctkově 20)
- při ukládání je MSb typicky nevyužitý
- 128–255 jsou volné
- rozšíření ASCII, tzv. codepage
- nestačí ani na všechny evropské znaky – Evropa se rozdělila na tři části
- ISO 8859-2 (ISO Latin2)
- 852 (DOS Latin2)
- Windows-1250
- nedá se napsat text, který by měl více kódování najednou (problém např. pro slovníky)
- Unicode
- 0–127 odpovídají ASCII
- běžné znaky jsou v rozsahu 0–$FFFF
- je tam rozsah, kde je garantováno, že daným kódům nikdy nebudou přiděleny žádné znaky
- „neběžné“ znaky v rozsahu $10000–$10FFFF
- UTF-32
- jeden znak 4 bajty
- UTF-32LE / UTF-32BE
- prakticky se nepoužívá
- UCS-2
- každý znak je dvoubajtový
- podporuje málo znaků
- UTF-16
- má proměnnou délku znaku – 2B nebo 4B
- 4B znak se zachycuje pomocí sekvence dvou dvoubajtových surrogate znaků (z nepoužívaného „déčkového“ rozsahu)
- UTF-16LE / UTF-16BE
- UTF-8
- proměnná délka znaku – 1, 2, 3, 4B
- princip kódování vícebytových znaků
- vícebytové znaky mají v prvním bytu MSb roven jedné
- pak počet bytů odpovídá počtu jedniček na začátku prvního bytu
- první byte sekvence začíná 11, další byty začínají 10
- neřeší se endianita
- nejběžnější kódování
- internet: UTF-8
- Windows: UTF-16LE
- když chceme text zobrazit uživateli – provedeme rasterizaci
- zalomení řádku
- CR (carriage return) – kód 13
- LF (line feed) – kód 10
- Windows: CR + LF
- Unix/Linux: LF
- Apple dříve: CR
- Unicode (v podstatě nepoužívané)
- LS – line separator
- PS – paragraph separator
- textový soubor jako posloupnost bytů
- v Pythonu otevřeme pomocí r nebo w
- řádky načítáme pomocí readline
- v Pythonu je text uložen pomocí Unicodu
- u příkazu open můžeme definovat kódování
- výchozí kódování je win-1250 (obecně podle operačního systému)
- chceme uložit binární soubor s textem (ale také dalšími daty)
- data
- 2B číslo
- 4B délka textu
- text
- 4B číslo
- pro převod na správný počet bytů můžeme použít funkci tobytes knihovny numpy
- bajty stringu můžeme získat pomocí funkce str.encode
- převod ze seznamu čísel na byty lze provést pomocí bytes()
- převod bytů na konkrétní data se provádní pomocí frombuffer(bytes, type)
- typ bytes je immutable
- typ byteArray je mutable
- bytes.decode – převede bajty na string
13. přednáška
- von Neumannovská architektura
- mezi procesor a paměť vložíme řadič paměti (memory controller)
- řadič paměti zajišťuje refresh DRAM paměti, takže pokud procesor ukládá během refreshe, tak se data pozdrží a uloží se do paměti po refreshi
- když chceme 1,5GB paměť, tak pořídíme dvě paměti (1GB a 0,5GB)
- řadič paměti je namapuje v adresovém prostoru, aby fungovala kapacita 1,5 GB (modul 0 mapuje na první paměť, modul 1 na druhou)
- procesor a paměť můžou mít různé komunikační protokoly – řadič to propojuje (to souvisí s velikostí adresových prostorů – např. procesor podporuje 8GB, ale paměti jenom 4GB, řadič umožňuje mít dvě 4GB paměti)
- chceme, aby z procesoru vedla pouze jedna sběrnice – budeme jí říkat systémová sběrnice, je na ni napojen řadič paměti i všechno ostatní
- každé zařízení na sběrnici má svou adresu
- každé zařízení má nějaké registry
- když oslovujeme zařízení, tak řekneme adresu zařízení a adresu registru, se kterým pracujeme – pak až pošleme data
- potřebujeme, aby ta sběrnice byla multidrop (abychom mohli připojit více zařízení)
- potřebujeme, aby ta sběrnice měla nějakou vlastnost, kterou I2C nemá – proto se jako systémová sběrnice typicky používá sběrnice PCI Express (PCIe)
- PCIe
- full duplex, multidrop
- dva druhy packetů (transakcí)
- adresace adresou zařízení
- adresace adresou v paměťovém adresovém prostoru
- memory write (MWr)
- memory read (MRd)
- procesor pošle požadavek
- řadič paměti si ho zapamatuje a začne na tom pracovat
- řadič v nějakém okamžiku pošle zpátky odpověď – řadič paměti vystupuje jako master, procesor jako slave, takže potřebujeme být schopni adresovat procesor
- zejména pokud máme více procesorů (nebo procesorových jader)
- v odpovědním packetu je kromě adresy procesoru také adresa řadiče paměti, aby si mohl procesor odpověď správně spojit s požadavkem
- jak oslovovat zařízení na systémové sběrnici?
- v paměťovém prostoru je obvykle spousta volného místa
- toto volné místo namapujeme na zařízení
- memory mapped I/O (MM I/O)
- zařízení řekneme bázovou adresu v adresovém prostoru
- z dokumentace zařízení zjistíme offset registru
- když to zkombinujeme s bázovou adresou, tak zjistíme, na kterou adresu zapisovat
- říká se tomu Host Controller Interface (HCI) – víme, co který registr dělá a na jakém je offsetu
- komunikační protokol je daný systémovou sběrnicí
- zvuková karta
- zvuk = tlak se mění v čase
- tlak budeme vzorkovat v čase – vždycky zaznamenáme jeho hodnotu
- sample … signed integer
- nekvalitní … 8-bit
- klasická kvalita … 16-bit
- kvalitnější … 24-bit
- v reproduktoru je membrána s elektromagnetem – podle napětí elektromagnet membránu přitahuje silně/slabě
- zvuková karta je jednoduchý digital analog converter (DAC) – podle vzorků vytváří napětí
- potřebujeme ve stejných intervalech, jako se zaznamenával vstup, udávat napětí
- sampling rate
- typicky 44,1 kHz
- někdy 22 kHz nebo 96 kHz
- potřebujeme cyklus, který bude dělat store do registru zvukové karty v daném (velmi přesném) intervalu
- bylo by hezké, kdybychom si mohli ve zvukové kartě připravit 1 ms předem (v bufferu) a zvuková karta by to následně přehrála (hodila by v tom bufferu po těch vzorcích a přehrávala by je)
- zvuková karta tedy musí mít sadu konfiguračních registrů, kam uložíme různé informace (velikost vzorku, vzorkovací frekvence)
- chceme mít n mikrofonů → n reproduktorů (mono/stereo/…)
- chceme spustit/ukončit přehrávání
- chceme nahrávat (tedy analog-digital converter)
- chceme znát aktuální stav zvukové karty (co zrovna přehrává)
- u zařízení s vícebytovými registry musíme řešit jejich endianitu (a případně převádět)
- chceme mixovat zvuk – průměrujeme dva vzorky (pokud mají různou hlasitost, tak děláme vážený průměr)
- dnešní zvukové karty mají HW akceleraci (CPU offloading) – typickým úkolem je právě mixování zvuku
- DSP (digital signalling procesor) – strojovým kódem tohoto procesoru můžeme ovládat, jak se má zvuková karta chovat
- řadič sběrnice
- procesor – PCIe – USB řadič – USB sběrnice
- takovým řadičům se říká HBA (Host Bus Adapter) – někdy také nesprávně bridge
- USB HBA je komplikovaný, takže se podíváme na I2C HBA
- průběh
- pošleme write do konfiguračního registru, aby se do start condition bitu nastavila jednička
- pomocí readu čekáme, až tam bude jednička
- ze stavového registru přečteme stav řadiče
- chceme poslat první (adresový) bajt
- zrušíme start condition bit
- …
- pošleme data
- …
- mnoho transakcí na systémové sběrnici na jednu transakci na I2C lince
- čekání = device polling, ztrácíme procesorový čas
- grafická karta
- je k ní připojený monitor
- obsahuje paměť (typicky DRAM) – „video RAM“
- v její části je frame buffer – tam je bitmapa stavu obrazovky
- karta x-krát za sekundu posílá monitoru obsah frame bufferu
- tradičně se používala analogová linka VGA
- dnes se používají digitální sériové linky DVI, HDMI, DisplayPort
- nechceme frame buffer obsluhovat pomocí registrů, bylo by to neefektivní
- frame buffer namapujeme do adresového prostoru, abychom do něj mohli zapisovat přímo
- mezi snímky je díra (aby se CRT paprsek mohl přesunout na začátek)
- registr grafické karty mi dává informaci o stavu vsync (že teď se právě paprsek přesouvá – je okamžik mezi snímky)
- v okamžiku mezi snímky můžeme změnit obraz (překopírovat data do frame bufferu nebo říct jinou bázovou adresu frame bufferu, pokud máme dva frame bufferu, které střídáme – tzv. princip double bufferingu)
- hardwarová akcelerace
- rasterizace textu
- kartě se nastaví textový režim
- má pole bitmap, které odpovídají znakům
- znaky přímo převádí na jim odpovídající bitmapy
- dnes se příliš nepoužívá
- rasterizace 2D
- rasterizace 3D
- do paměti nahrajeme mesh 3D modelu (trojúhelníky) a odpovídající textury, kterými se mesh pokryje – engine podle toho generuje obsah frame bufferu
- moderní grafická karta má procesor
- programu pro takový procesor se říká shader
- jak dostat kód na von neumannovskou architekturu
- jeden z paměťových modulů může být non-volatile – ROM
- vykonává základní program, budeme mu říkat firmware
- procesor má nastavený startup vector, což je adresa, kam se procesor nastaví po zapnutí
- na té adrese je typicky jump, který směřuje jinam na reálný kód firmwarové ROM
- funkce firmwarové ROM
- bootování počítače
- test a konfigurace hardwaru
- plug & play – každému zařízení se přiřadí jiná bázová adresa a funguje to
- nalezení užitečného softwaru
- provede se jump na option ROM, kde je užitečný software (třeba editor a interpret basicu)
- myšlenka, že bychom chtěli distribuovat programy
- koupím si cartridge
- zapojím ji do počítače
- namapuje se jako další option ROM
- je tam nějaký magic
- užitečný software taky může být na mass storage device
- pevný disk je rozdělený na sektory, je to zformátované souborovým systémem
- nultý sektor je speciální – boot sector
- může tam být strojový kód něčeho užitečného, co by se mělo spustit
- je tam magic, který určuje, jestli je to zařízení bootovatelné (jestli v boot sektoru je něco rozumného)
- jednotlivá zařízení (třeba grafická karta) mají své option ROM
- v boot sektoru je typicky pouze část užitečného softwaru – bootloader
- další funkce – firmwarové ROM: abstrakce nad hardwarem
- funkce read sector, read key, print char
- aby bootloader mohl používat tyto základní funkce
- kdysi na jedné disketě jeden program
- dnes si chceme vybírat z různých programů
- jádro operačního systému (kernel)
- poskytuje abstrakci souborového systému
- abstrakce HW (lepší než firmware) – vstup/výstup (klávesnice, myš, text, grafika)
- spouštění programů
- typicky to nejprve spustí tzv. shell, aby si uživatel mohl vybrat, jaký program chce spustit
- shell může být textový nebo grafický
- více programů současně – programy se střídají (je to zjednodušení, více na počítačových systémech)